
ちょっと古い内容になりますが、SQLServerのデータベース破損に関して記載しています。データベース破損とは何か?やデータベースの破損原因、データベースの破損状況の分析と復旧方法などについて記載します。
データベースの破損とは
まず、そもそもデータベースの破損とは何か。あるいは、どのような場合にSQL Serverは「データベースが破損している」と判断するのか。
データベースの物理的な破損
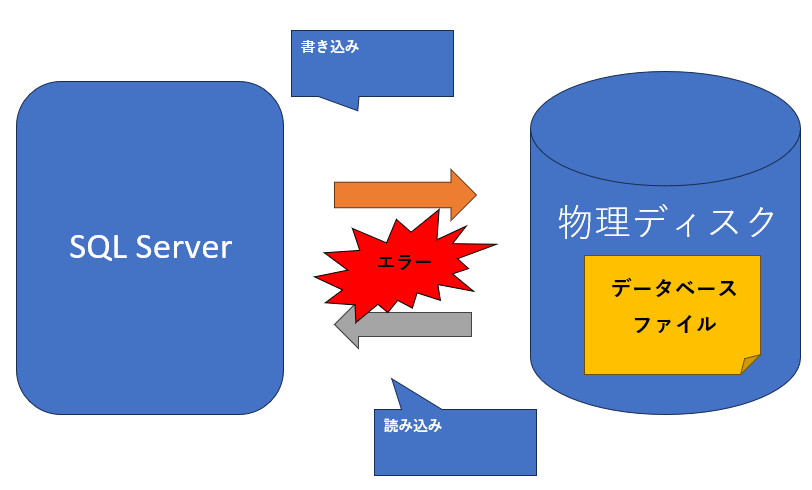
SQL ServerがディスクI/Oを行なうときに使用するAPI(ReadFileScatterやWriteFileGather等)を実行した際に、ディスクにアクセスできないなどのハ ードウェア障害が起きて、Windowsオペレーティングシステムからエラーが返されることがあります。 つまり、ディスク上の物理ファイルに対する読み込みや書き込みができない状態です。
このような場合、SQL Serverはクライアント側にエラーを返しエラーログに情報を出力します。また、SQL Serverの起動時やバックアップからの復元時に、このような物理的な破損が検出されるとSQL Serverはそのデータベースに対して 「未確認」というステータスを設定しアクセスを遮断します。 これによって、破損が発生したデータベースへのアクセスを未然に防止しているのです。
図1:データベースの物理的破損
データベースの論理的な破損
ディスク上の物理ファイルへのアクセスは成功したが、読み込んだデータの管理情報やデータの内容が意図した状態ではないという場合は、データベースが論理的に破損しています。それらの情報が不正な状態だと、たとえデータを読み込めたとしても、SQLServerは意図した操作を正しく実行できません。そのため、物理的な破損と同じく、クライアントへエラーを返し、エラーログに情報を出力します。また、SQLServerの起動時やバックアップからの復元時に検出された際も、同様に「未確認」というステータスが設定されます。次に論理的破損の例を挙げてみます。
ページIDリンクとオブジェクトIDの不整合
データベースは8KBのページに分割されていて、各ページはユニークなページ番号を持っています。また、各ページはオブジェクトが使用されているかを示すために、オブジェクトIDを持っています。
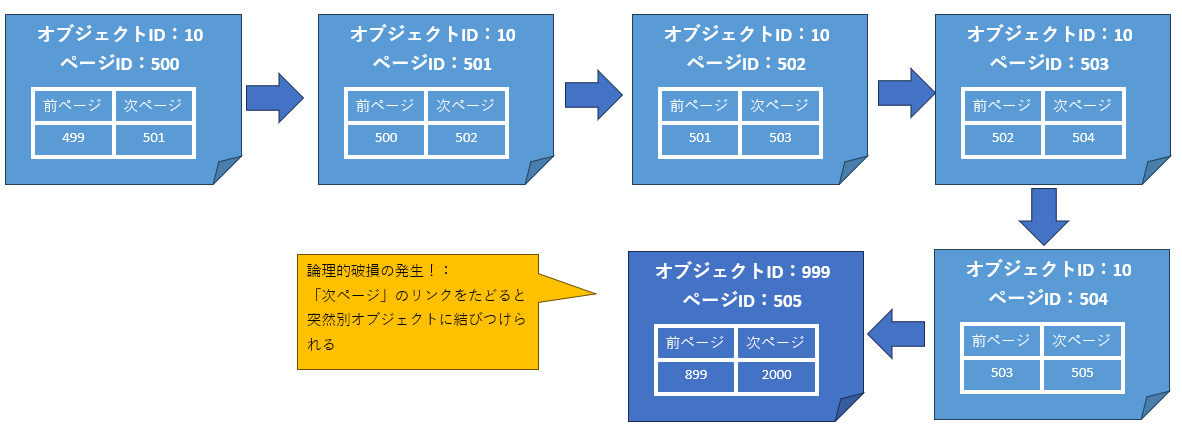
SQLServerはデータを取得する際に、ページIDのリンクを使用することがあります。例えば、テーブルAのデータを取得する際は、テーブルAに該当するオブジェクトIDを持つ各ページを、ページIDのリンクチェーンをたどって取得します。ページIDのリンクチェーンは、同一オブジェクト内で閉じている必要がありますが、論理的破損が発生すると、突然別のオブジェクトに属するページにリンクされることがあります(図2)。
図2:データベースの論理的破損
データベースの破損が発生する理由
データベースの物理的破損に関しては、破損原因の特定は比較的容易な場合が多くなります。なぜなら、ディスク上のデータベースファイルへのI/Oが行なわれたときに、Windowsオペレーティングシステムからエラーが返されるため、データベレースの破損とハードウェアの問題に関連があると推測することは容易だからです。
また、そのようなエラーが発生した場合には、Windows管理ツールのイベントログなどに障害の発生が示されていることも多く、より詳細な情報を得られる場合もあります。
一方、データベースの論理的破損についてはどうでしょうか。特にハードウェアに関するエラーが発生することなく、ある時点で突然データベースの破損が検出されたりします。イベントログを確認しても、SQLServerが破損を検出した際に出力するエラーばかりが数多く記録されています。
さらには、データベースへアクセスしようとしたクライアントにはSQLServerから破損に関するエラーが返されるばかりです。そのため、「SQLServerがデータベースを壊した」と思い込むユーザーも少なくありません。しかし、果たして本当に原因はSQLServerだけにあるのでしょうか。まずは、論理的破損の発生パターンから確認してみましょう。論理的破損が検出されるパターンは大別すると次の2つです。
- ディスクへ書き込むべき内容がすでに不正
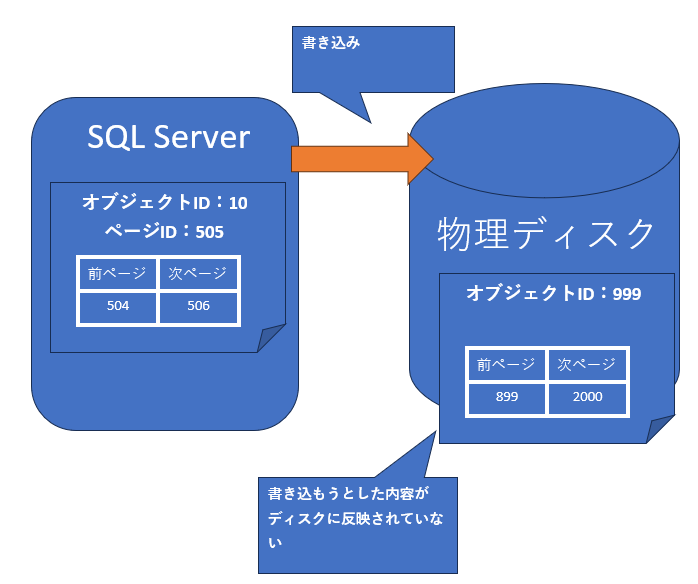
- ディスクに書き込まれるべき内容が書き込まれなかった。
図3:不正な書き込み
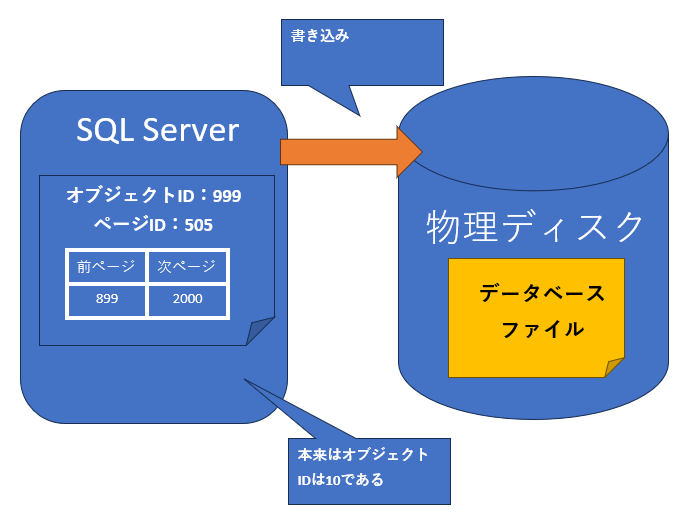
図4:書き込み動作に不具合
1.のケースは、SQLServerの動作に問題がある可能性があります。その理由は、ディスクに書き込まれるべきデータキャッシュやログキャッシュ上のデータはSQL Serverのみから操作可能だからです。かつて、SQLServer6.5以前のバージョンでは複雑なデータベースページのリンク形態などが災いして、SQL Server自体が論理的不整合を発生させる不具合がいくつか報告されています。
しかし、データベースの構造が根本的に見直されたSQLServer7.0以降であれば、1.に該当する問題はほとんど存在しません。一方、2.の動作は、一般的に「stale read(古いデータの読み取り)」または「lost write(書き込みの消失)」と呼ばれいます
2の動作が原因と推測される原因は数多くあります。そのいくつか記載します。
データの破損は過去のある時点で発生している
データの破損は、ディスクからデータが読み込まれた時点で発覚します。ただし、データの破損が発生したのはデータがディスクへ書き込まれた時点です。数秒前かもしれませんし、あるいは数日前である可能性もあります。そのため、破損が検出された時点ではじめて何かを調査しようとしても、破損発生当時の情報が残っていることはほとんどありません。
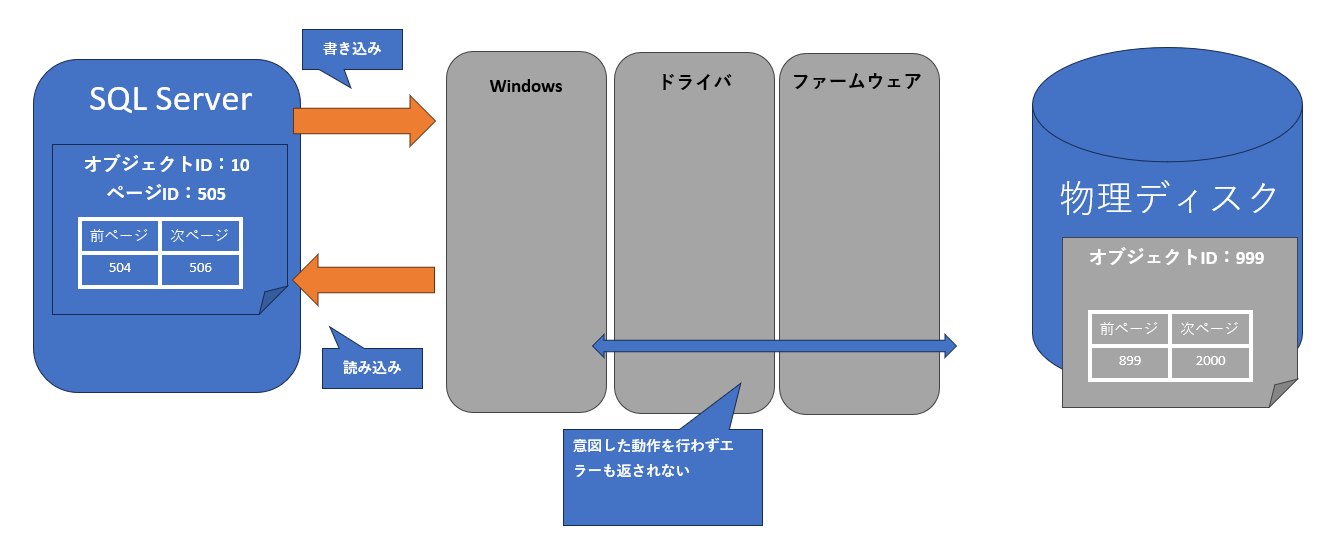
Windowsオペレーションシステムからエラーが返されない
SQL Serverがディスクへの書き込みに使用するWin32API実行時に何らかのエラーが返されるなら、その時点で障害を検知できますが、しかし、Win32APIよりも下位レベルのドライバやファームウェアが正しく機能せず、さらに何のエラーも上位のWin32APIへ返さない場合は、SQL ServerやWindowsオペレーションシステムには何も検知できません。
図5:Win32APIより下位レベルでエラー
イベントログにも情報が記録されない
イベントログに情報を書き込むためには、エラーが発生したことを自ら検知する必要があります。ドライバやファームウェアで不正な動作があった場合でも、Win32APIにはエラーが返されません。そのため、イベントログへ情報を書き込むための動作もされません。
stale readとlost write
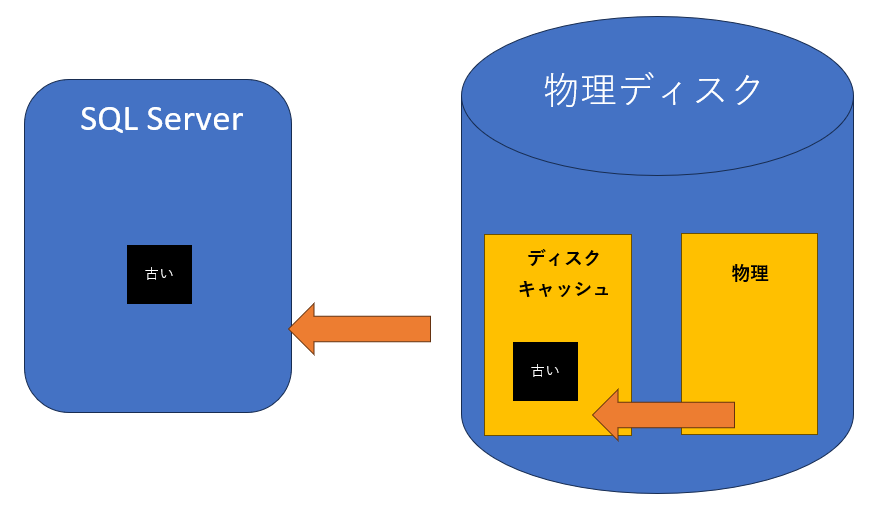
データベースの破損が頻繁に発生する複数のハードウェア環境で、詳細な検証を行った結果、次のような動作の結果としてデータベースが破損する場合があることが確認された。また、lost write(書き込みの消失)を使用しています。同じハードウェアを使っていても、常にstale readやlost writeが発生するわけではなく、とても高い負荷でディスクI/Oが行われている場合のみ発生する傾向があります。
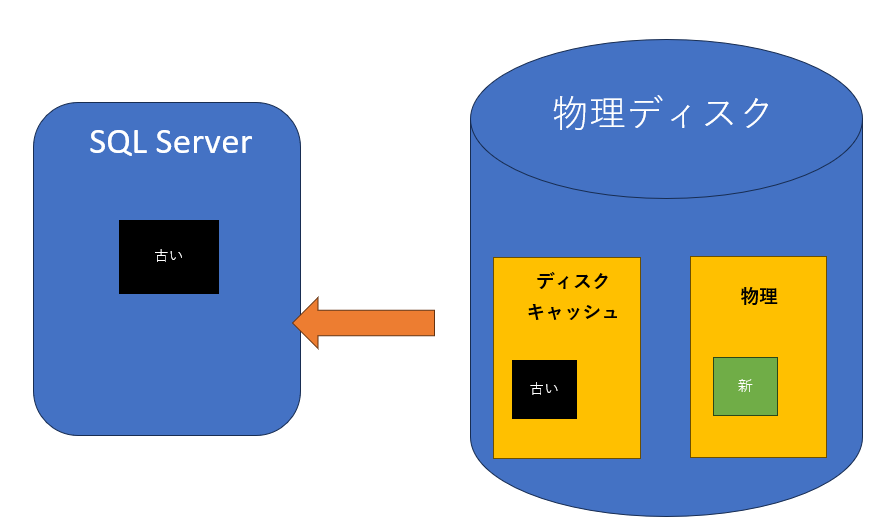
stale read(古いデータの読み取り)
ReadFileScatterまたはReadFile APIは正常に完了。しかし、ドライバやキャッシュコントローラの不正な動作のために、誤って古いデータが返される。
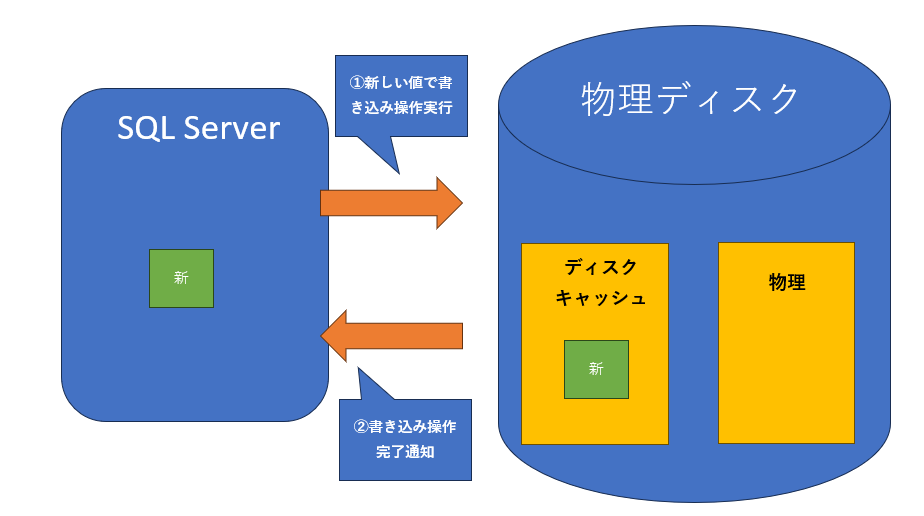
lost write(書き込みの消失)
WriteFileGatherまたはWriteFile APIは正常に完了。しかし、ドライバもしくはキャッシュコントローラの不正な動作のために、データが物理ディスク上のファイルに正しくフラッシュされない。
1.SQL Serverは書き込み操作を完了して、完了通知を受け取る
2.ディスクキャッシュのデータは物理ディスクにフラッシュされない
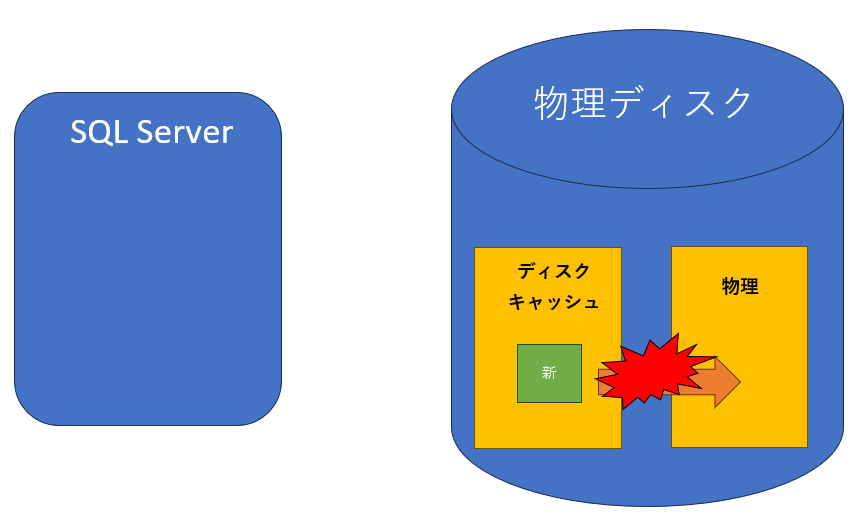
3.次に物理ディスクからの読込が必要になった場合に、古いデータが返される
データベース破損の検出
SQL Serverには、データベースの破損を可能なかぎり早く検出するための機能が組み込まれています。また、それらの情報は、データベースが破損した原因を追究するための手掛かりにもなります。それらを有効に利用するために、それぞれの特徴や機能を紹介します。
Torn page
Torn pageは「傷ついたページ」という意味です。SQL Server 7.0以降のバージョンで、Torn page検出機能が実装されています。Torn pageを検出するために実装しているアルゴリズムは、次のようなものです。
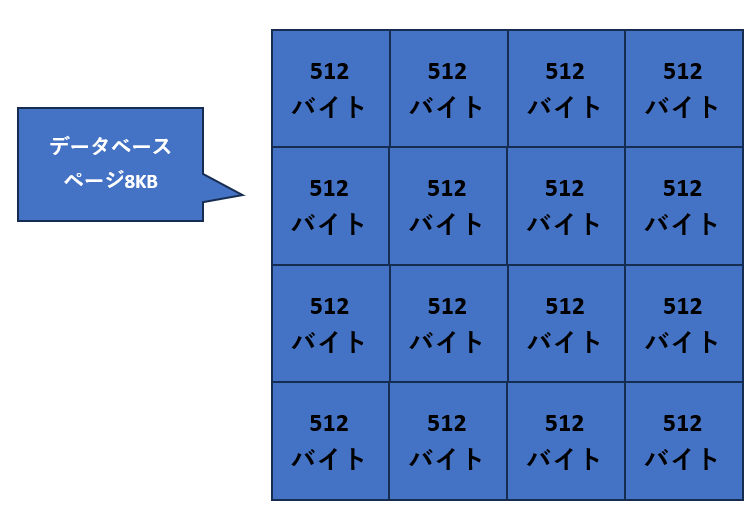
1.8KBを512バイトのセクタに分割する(1ページあたり16個のセクタで構成)
データベースの各ページは8KB(512バイトのセクタ16個で構成)
図6
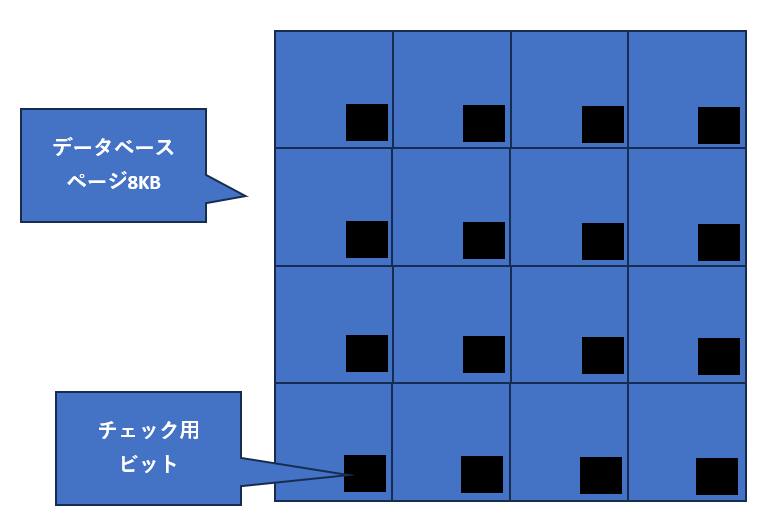
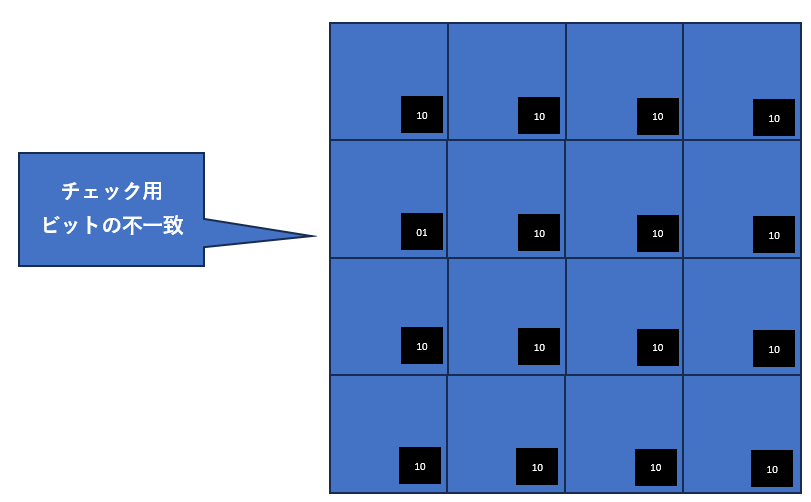
2.各セクタにTorn pageチェック用ビットを確保する
各セクタの最後尾2ビットがTorm page検出用に使用される
図7
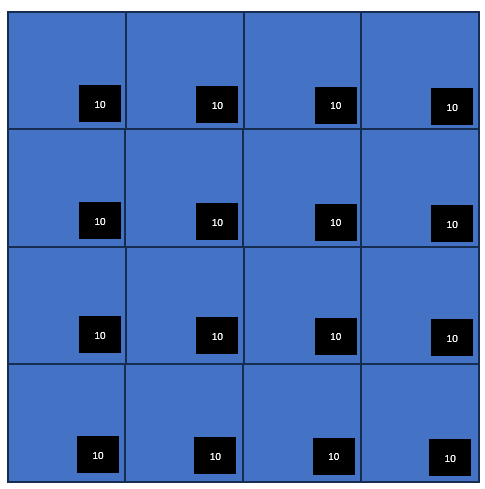
3.ディスクへの書き込みを行うために、16セクタのチェック用ビットすべてを01もしくは10に書き換える
4.SQL Serverのデータページ及びインデックスページのサイズは8KBなので、8KB以下のサイズでの書き込み命令は行われない。そのため、各ページ内の16個のチェック用ビットは常に同じ値を示している
書き込みが行われると、ページ内のすべてのチェック用ビットが書き換えれる。
チェック用ビットが10の場合01へ変更
チェック用ビットが01の場合10へ変更
図8
5.もし、1個でもほかのセクタと異なる状態のチェック用ビットが検出された場合は、8KBのページの一過性が損なわれたことを示している。SQL Serverは8KB以下の書き込み命令を行わないため、ハードウェア障害などでチェック用ビットが一致しないセクタへの書き込みが正しく行われなかった証拠となる。(図9)
チェック用ビットの値が同一ページのほかのセクタと一致しない場合は、正しくディスクへ書き込まれていないことを示している
図9
Tornpage検出機能の有効化
use データベース名
go
exec sp_dboption 'torn page',1
goTorn page検出機能を有効化しても、既存のデータベース内のページへの対処は行ないません。この機能は、新たに書き込まれるページに対してのみ有効です(SQLServer7.0およびSQLServer2000ではデータベース作成時のデフォルト設定として有効化されています)。
チェックサム
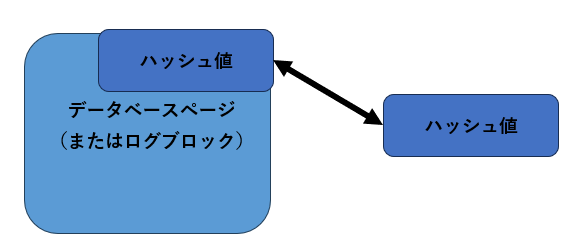
SQLServer2005から導入された機能の1つがチェックサムです。バッファキャッシュ上のページやログブロックをディスクへ書き込む前に、それぞれの内容を基にハッシュ値を計算します。生成されたハッシュ値はページやログブロックのヘッダ一部分に保持されます。
ハッシュの値の保存
図10
1.ページ/ログブロック内の値を基にハッシュ値を計算
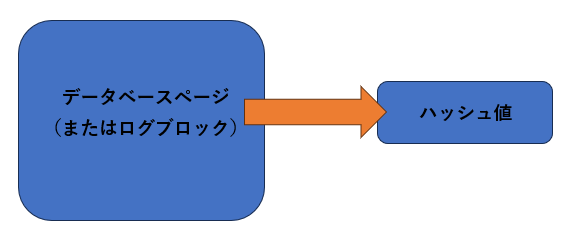
2.ハッシュ値をヘッダー情報として保存
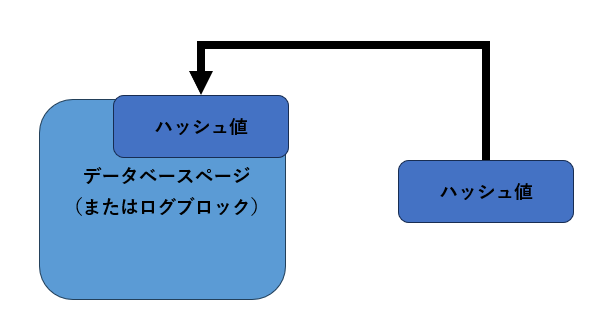
ページやログブロックが読み込まれたときに、再度それぞれの内容を基にハッシュ値を計算して、ヘッダー部分に格納された値と比較します。もしも双方の値が一致しない場合は、何らかの障害によってディスクへの書き込みが発生したと考えられます(図11)。
ハッシュ値の比較
図11
1.ページ/ログブロック内が読み込まれるとハッシュ値を計算
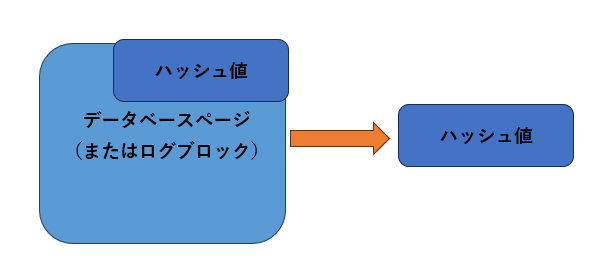
2.新たに計算したハッシュ値とヘッダー内のハッシュ値を比較
チェックサム機能を有効化するには、次の手順を実施してください。チェックサム機能を有効化しても、既存のページとログブロックの検証は行ないません。新たに書き込まれたページやログブロックから、この機能が有効化されます(SQLServer2005以降ではデータベース作成時のデフォルト設定として有効化されています)。
- クエリツール(osql、sqlcmd、クエリアナライザ、SQL Server Management Studioなど)でSQL Serverに接続する
- 以下のコマンドを実行
alter database データベース名
PAGE_VERIFY CHECKSUM
goTorn page検出機能が各セクタのビットのみで正当性を検証しているのに対して、チェックサムはページやログブロック全体の値を基に検証を実施しています。そのため、チェックサムのほうがより厳密なチェックが可能と言えます。ただし、厳密なチェックを行なっている分、オーバーヘッドが発生します。どちらを使用するかは、パフォーマンステスト結果で選ぶ必要があります。
メモリ上のチェックサム
SQLServer2005からは、さらにバッファキャッシュに読み込まれたページに対してもチェックサムを使用して正当性の検証を行なうことができます。メモリ上でのチェックサムによる検証が行なわれるタイミングは、ダーティページがディスクへ書き込まれて、ページのステータスがクリーンへと変更される時点です。メモリ上のチェックサム機能を有効化するには、次の手順でSQLServerにトレースフラグ831を設定する必要があります。また、メモリ上のチェックサムを実施する際に使用するハッシュ値は、前述のチェックサムと同じものを共通して使用します。そのため、トレースフラグとともにチェックサムも有効化しておく必要があります。
- SQLServer構成マネージャを起動する
- SQLServerインスタンスを右クリックして[プロパティ]を選択
- [詳細設定]タブの[起動時のパラメータ]をクリックする
- 最後尾に文字列「;-T831」を追加する
- [適用][OK]をクリックする
- SQLServerを再起動する
トレースフラグ818
トレースフラグ818は、SQLServer2000SP4と、SQLServer2005以降で使用できる機能です。この機能を有効化すると、SQLServerはディスクへの書き込み命令が成功した際には、書き込んだデータの管理情報を一定回数分(2048回)保持しておきます。もしデータベースの破損が検出された際には、保持していた管理情報と破損箇所の管理情報を比較します。もし両者の値が一致しない場合は、stalereadもしくはlostwriteが発生していると推測されます。この機能の有効化の方法は次のとおりです。
SQL Server 2005以降の場合
- SQLServer構成マネージャを起動する
- SQLServerインスタンスを右クリックして[プロパティ]を選択する
- [詳細設定]タブの[起動時のパラメータ]をクリックする
- 最後尾に文字列「;-T818」を追加する
- [適用][OK]をクリックする
- SQLServerを再起動する
SQL Server 2000SP4の場合
- SQLServerEnterpriseManagerを起動する
- 2SQLServerインスタンスを右クリックして[プロパティ]を選択する
- [起動時のパラメータ]をクリックする
- [パラメータ]テキストボックスに文字列「-T818」を追加する
- [追加][OK]をクリックする
- SQLServerを再起動する
データベース破損の状況分析
データベースの破損が検出されてしまった場合や、ステータスが「未確認」に設定された場合(コラム「緊急モードへの設定法」を参照)は、次にとるべき行動はデータベースの破損状況を正確に把握することです。破損の程度によって、復旧のための作業や復旧が完了するまでの時間は大きく違ってきます。
緊急モードへの設定法
ステータスが「未確認」に設定されたデータベースには、そのままではアクセスできないため、破損状況を把握できません。そのため、いったんステータスを変更して「緊急」モードに設定する必要があります。クエリツールでSQLServerインスタンスに接続して、次のコマンドを実行すると、データベースが緊急モードに設定されます。
alter database データベース名 set emergency go破損状況を把握するためのコマンド
SQLServerには破損状況を確認するためのツールとして、次のコマンドが用意されています。クエリツール(osqlsqlcmd、クエリアナライザ、SQLServer Management Studioなど)でSQLServerインスタンスに接続してこのコマンドを実行すると、データベースの状況が確認できます。
dbcc checkdb(データベース名')
goこのコマンドを実行すると、次の情報の整合性が確認されます。破損したデータベースはいずれかのデータ構造に不整合が発生しているため、コマンド実行時には破損箇所を示すメッセージが出力されます。その内容を基にデータベースの破損状
況を確認できます。
- データベース内の各ページが正しくリンクされていること
- インデックスが正しい並べ替え順序で並んでいること
- ページオフセットが適切であること
- ベーステーブルと各非クラスタ化インデックスのすべての行が、それぞれに対応していること
- パーティションテーブルやパーティションインデックスのすべての行が、正しいパーティションにあること
破損状況の確認方法
dbcc checkdbを破損したデータベースに対して実行すると、破損のために発生したデータの不整合1つ1つについて、メッセージが出力されます。そのため、破損箇所が数多く存在する場合は、出力されるメッセージの量は膨大になり、その内容も多岐にわたることになります。各メッセージに出力されている内容をすべて確認しても、多くの場合はあまり意味がありません。
確認ポイント1:オブジェクトID
オブジェクトIDとは、データベース内のオブジェクト(テーブルやビューなど)に割り当てられたユニークな識別子です。不整合を示すメッセージが数多く出力されていても、この値が常に同じなら1つのオブジェクトのみで破損が発生しています。メッセージ数が少なくても、オブジェクトIDがすべて違う値であれば複数のオブジェクトが破損しています。また、クエリツールで次のクエリを実行すると、オブジェクトIDから実際のオブジェクト名を確認できます。
use データベース名
go
select object_name(オブジェクトID)
go確認ポイント2:インデックスID
インデックスIDが「0」の場合はヒープ(クラスタ化インデックスが定義されていないテーブルのデータページ)、「1」の場合はクラスタ化インデックスのリーフページを示しています。「2」以上の場合は非クラスタ化インデックスです。破損箇「所が「0」「1」の場合とそれ以外では対処方法が大きく変わる場合があります。詳細は対処方法の節で解説します。
dbcc checkdb実行時に考慮すべき点
システムへ与える負荷
dbcc checkdbでは、データベース内の割り当て済みのページの整合性を検証します。そのため、対象となるデータベースの規模が大きくなると、大量のデータをバッファキャッシュ上およびtempdbにスプールする必要が発生します。
コンパイル済みプランの消去
SQL Server 2005 SP1以前のバージョンでは、dbcc checkdbが実行されると、プロシージャキャッシュ上のコンパイル済みプランが消去されていました。そのため、コマンド実行後にクエリの再コンパイルが多発して、パフォーマンスが一時的に低下することがあります。SQL Server 2005 SP2以降では、コンパイル済みプランは消去されません。
dbcc checkdbが改良された点
SQL Server 2005からの大きな改善点は、内部的に作成したデータベースに対してチェックを行なう動作です。SQL Server 2000以前のバージョンでは、更新処理が行なわれているデータベースに対してdbcc checkdbを実行すると、破損やデータ構造の不整合が誤って報告されることがありました。それは、更新系処理の途中でdbcc checkdbが実行されると、ページの割り当てなどが完了する前にデータ構造のチェックが行なわれることがあり、不整合が発生しているように見えてしまうためでした。
データベースをシングルユーザーモードに設定してdbcc checkdbを実行すれば、そのような問題は発生しません。しかし、運用環境でデータベースをシングルユーザーモードに変更することは、多くの場合に現実的ではありません。そこで、dbcc checkdb実行用のデータベーススナップショットを内部的に作成して、整合性の確認を行なうように実装が変更されました。これにより、不整合が誤ってレポートされる問題や、dbcc checkdbとほかのクライアントとの間のブロッキングの問題が解消されました。
データベース破損への対応
データベース破損への対処
根本的な問題の解決
データベースの破損が発生した場合、通常は、まず何よりもデータベースを再度使用できる状態にすることを最優先します。短期的に見れば、システムダウンの時間をできるだけ少なくするための対処は効果的です。しかし、破損の原因がハードウェア障害やドライバの不具合であった場合を考えてみてください。一時的にシステムは復旧しますが、将来的に破損が再発する危険性が高くなります。
そのような不安定な状況での運用を避けるために、多少システムダウンの時間が長くなったとしても、可能であれば原因追究と対処を行なっておくことをお勧めします。前述したいくつかの機能は、破損発生時の問題の切り分けに効果を発揮します。併せて、次の対処でも原因追究につながる問題の切り分けが可能です。
ディスクライトキャッシュの無効化
データベース破損が頻発し、かつ破損箇所がランダムに発生する場合は、高負荷時のディスクキャッシュの動作に問題が起きている可能性が高くなります。この場合、障害が発生するディスクのライトキャッシュを無効化すると、問題の切り分けが進むことがあります。
ストレスツールの使用
マイクロソフトのダウンロードサイトから、SQLIOSIMストレスツールをダウンロードできます。このツールは、SQLServerと類似したI/Oパターンを生成してディスクに負荷をかけられます。ツールによって負荷をかけるため、潜在的なドライバやハードウェアなどの問題を発見できます。
バックアップからの復旧
データベースバックアップおよびトランザクションバックアップからの復旧は、データベース破損の発生時に、最も推奨される対処方法です。計画的にデータベースの全体バックアップと、トランザクションバックアップが取得されていれば、データベース破損が検出される直前まで復元することができます。
バックアップからの復旧以外の対処
非クラスタ化インデックスの削除/再作成
破損箇所がヒープおよびクラスタ化インデックスの場合と、非クラスタ化インデックスでは状況が大きく異なります。非クラスタ化インデックスは、ヒープやクラスタ化インデックスを一次情報として作成するため、二次的な生産物とも言えます。そのため、もしも非クラスタ化インデックスが破損しても、オリジナルのデータを保持しているヒープやクラスタ化インデックスが無事ならば、何度でも作り直すことができます。dbcc checkdbの実行結果にインデックスIDが2以上のページの不整合が出力された場合は、非クラスタ化インデックスの削除と再作成が有効です
再起動
stale readの結果として不整合が発生している場合、システム全体を再起動して、すべてのデータをディスクから再度読み込ませると障害が解消される場合があります。その際にはコンピュータのみではなく、データベースファイルを配置しているディスクシステムも再起動しないと効果が得られません。
修復オプション付きdbcc checkdb
dbcc checkdbは整合性を確認するだけでなく、「修復オプション」を指定することにより不整合が発生している箇所の修正を試みることもできます。指定できる修復オプションには、軽度な修復を行なうREPAIRFAST、インデックスの再構築などを含むREPAIR_REBUILD、整合性確保のためにデータ消失を伴う可能性のあるREPAIR_ALLOW_DATA_LOSSがあります。修復オプション付きのdbcc checkdbのコマンドは、次のようにデータベース名の後にオプションを指定します。
dbcc checkdb(データベース名',REPAIRFAST)
go破損したデータベースを修復するために必要なオプションは、dbcc checkdbの出力結果の最終行に次のように示されます(不整合が検出された場合のみ出力される)。
REPAIRFASTはDBCC CHECKDB(データベース名)で見つかったエラーの最小修復レベルです。また、使用する際にはいくつかの注意点があります。まず、100%の確率で修復が完了するわけではないということです。修復オプション付きdbcc checkdbを実行しても、常に修復が完了するわけではありません。
また、修復オプション付きdbcc checkdbを使用するためには、データベースをシングルユーザーモードに設定する必要があります。そのため、コマンドが完了するまでの期間は、データベースの正常な箇所のデータへのアクセスもできなくなります。データベースをシングルユーザーモードに設定するには、次のコマンドをクエリツールから実行してください。
alter database データベース名 set single_user
go3つ目の注意点は、データの消失が発生するオプションがあるということです。REPAIR_ALLOW_DATA_LOSSオプションは、データベース内の管理情報の整合性を正しい状態へ修復することを優先します。その結果、整合性がとれない箇所をオブジェクトから切り離してしまう可能性があります。
