よく利用する正規表現の「最長一致と最短一致」、「名前付きキャプチャグループ」、「グループの後方参照」、「後読みと先読み」、「ひらがな/カタカナ/漢字などを取得」について解説しています。
最長一致と最短一致
最長一致とは、正規表現で「*」「+」などの量指定子を利用した場合に、できるだけ長い文字列を一致させないさいというルールです。
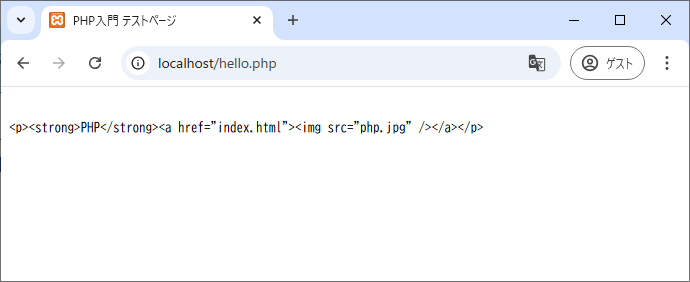
<?php
$tags = '<p><strong>PHP</strong><a href="index.html"><img src="php.jpg" /></a></p>';
if (preg_match_all('/<.+>/', $tags, $data, PREG_SET_ORDER)) {
foreach ($data as $item) {
print htmlspecialchars($item[0]). '<br />';
}
}これが「できるだけ長い」文字列を一致させる、最長一致の挙動です。
「<.+>」は、<…>の中に「.」(任意の文字)が「+」(1文字以上)で<strong>や<img>のようなタグにマッチします。
個々のタグを取り出したい場合
if (preg_match_all('/<.+?>/', $tags, $data, PREG_SET_ORDER)) {のように修正します。「+?」は最短一致を意味し、今度は「できるだけ短い文字列を一致」させようとします。
名前付きキャプチャグループ
正規表現パターンに含まれる(…)でくくられた部分のことを、グループ、またはキャプチャグループと言うのでした。マッチした文字列を「$imte[1]」のようにインデックス番号で参照していましたが、グループに意味ある名前を付与することもできます。これを名前付きキャプチャグループと言います。
<?php
$str='会社の電話番号は0399-99-1123、私のは0388-22-1234です。郵便番号は666-1105です';
if(preg_match_all('/?P<area>([0-9]{2,4})-(?P<city>[0-9]{2,4})-(?P<local>[0-9]{4})/',$str,$data,PREG_SET_ORDER)){
foreach($data as $item){
print "電話番号:{$item[0]}<br />";
print "市外局番:{$item['area']}<br />";
print "市内局番:{$item['city']}<br />";
print "加入者番号:{$item['local']}<hr />";
}
}名前は、グループの先頭で?P<…>の形式で宣言するだけです。この例では、市外局番(area)、市内局番(city)、加入者番号(local)をそれぞれ命名していきます。これら名前付きキャプチャグループにアクセスするには、配列のキーとして文字列を渡せます。
グループの後方参照
グループにマッチした文字列は、正規表現パターンの中であとから参照することもできます(後方参照)。
例:文字列から「<a href=”…”>…</a>」を取り出す。
一般的なグループは「\1」のような番号で後方参照できます。もちろん、複数のグループがある場合は、\2、\3…のように指定します。
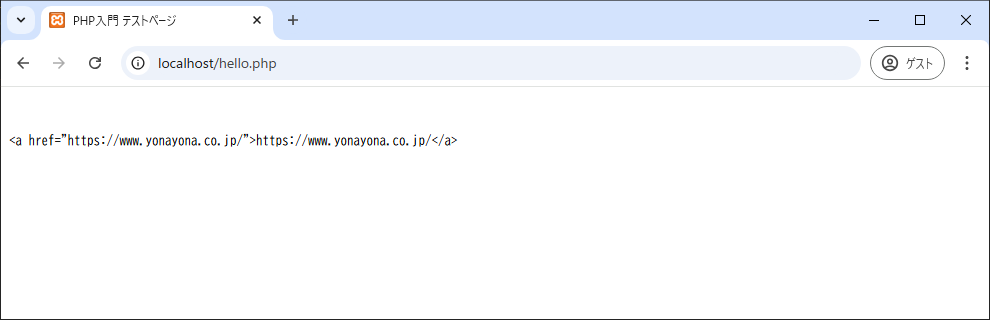
<?php
$str='<p>サポートサイト<a href="https://www.yonayona.co.jp/">https://www.yonayona.co.jp/</a></p>';
if (preg_match('/<a href="(.+?)">\1<\/a>/', $str, $data)) { //➊
print htmlspecialchars($data[0]);
}
名前付きキャプチャグループも利用できます。その場合は、➊を以下のように書き換えます。
if (preg_match('/<a href="(?P<link>.+?)"><?P=link><\/a>/', $str, $data)) {名前付きキャプチャグループを参照するには「(?P=名前)」とします。
参照されないグループ
正規表現では、パターンの一部を(…)でくくることで、部分的なマッチング文字列を取得できるのでした。ただし、(…)はサブマッチの目的だけで用いるばかりではありません。たとえば、「*」「-」の対象をグループ化するために用いるような状況もあります。
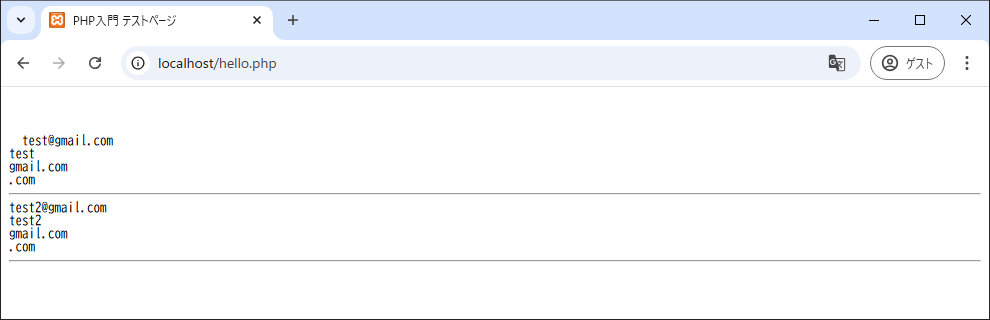
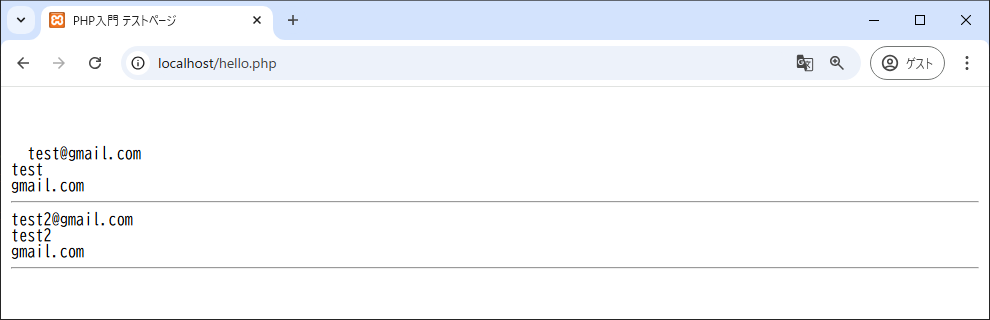
<?php
$str = "仕事のメールアドレスは、test@gmail.comです。プライベート用は、test2@gmail.comです。";
if(preg_match_all("/([a-z0-9.!#$%&\'*+\/=?^_{|}~-]+)@([a-z0-9-]+(\.[a-z0-9-]+)*)/i",$str,$data, PREG_SET_ORDER)){ //➊
foreach ($data as $item){
print "{$item[0]} <br />";
print "{$item[1]} <br />";
print "{$item[2]} <br />";
print "{$item[3]}"; //➋
print "<hr />";
}
}
この例では、正規表現パターン(❶)に3個のグループが含まれています。しかし、3番目のグループは「*」の対象を束ねるためのもので、サブマッチを目的としたものではありません。そのようなグループは、あとから参照する際にも間違いのもとになりますし、そもそも参照しない値を保持しておくのはリソースの無駄です。
そのような場合には、(?:…)とすることで、サブマッチの対象から除外できます。たとえば➊を以下のように書き換えます。
if(preg_match_all("/([a-z0-9.!#$%&\'*+\/=?^_{|}~-]+)@([a-z0-9-]+(?:\.[a-z0-9-]+)*)/i",$str,$data, PREG_SET_ORDER)){3番目のグループが存在しなくなった結果、「Undefined array key 3 ~」(3番目のグループが存在しない)のようなエラーが発生します。
➋をコメントアウトするとことで、以下の実行結果が得られます。
後読みと先読み
前後の文字列の有無によって、本来の文字列がマッチするかを判定することもできます。
| 表現 | 概要 |
|---|---|
| A(?=B) | 肯定的先読み(Aの直後にBが続く場合にだけ、Aにマッチ) |
| A(?!B) | 否定的先読み(Aの直後にBが続かない場合にだけ、Aにマッチ) |
| (?<=B)A | 肯定的後読み(Aの直前にBがある場合にだけ、Aにマッチ) |
| (?<!B)A | 否定的後読み(Aの直前にBがない場合にだけ、Aにマッチ) |
例:
先読み、後読みにかかわらず、カッコの中はマッチング結果には含まれません。また、➊は先に「。」がない「いろ」を検索するので、「。いろ」が除外され、2個の「いろ」を拾っています。
<?php
// 与えられたパターンと入力文字列でマッチした結果を表示
function showMatch($ptn, $input){
if(preg_match_all($ptn, $input, $data)){
foreach ($data as $items) {
foreach ($items as $item) {
print "{$item}<br />";
}
}
}else{
print 'マッチしません。<br />';
}
print '<hr />';
}
$re1 = '/いろ(?=はに)/';
$re2 = '/いろ(?!はに)/';
$re3 = '/(?<=。)いろ/';
$re4 = '/(?<!。)いろ/';
$msg1= 'いろはにほへと';
$msg2 = 'いろものですね。いろいろと';
showMatch($re1, $msg1);
showMatch($re1, $msg2);
showMatch($re2, $msg1);
showMatch($re2, $msg2);
showMatch($re3, $msg1);
showMatch($re3, $msg2);
showMatch($re4, $msg1);
showMatch($re4, $msg2);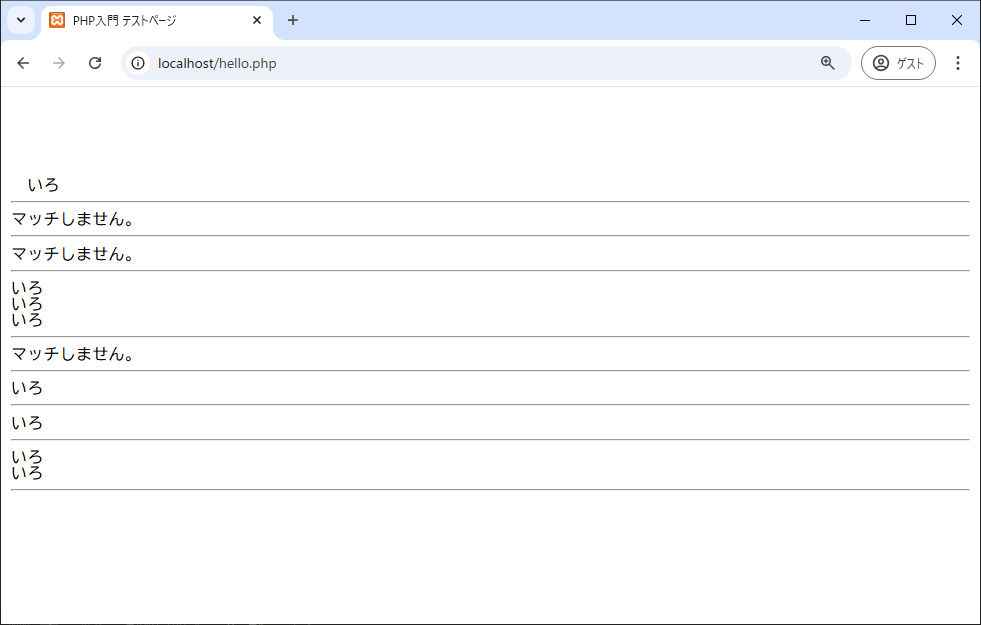
ひらがな/カタカナ/漢字などを取得する
Unicodeの個々の文字には、それぞれの文字種を表すためのプロパティが割り当てられています。これらプロパティを正規表現パターンの中で利用できるようにしたものがUnicodeプロパティという仕組みです。Unicodeプロパティを利用するには、UTF-8モード(u修飾子)を有効にした上で、\p{…}の形式で表します。
Unicodeプロパティ
| プロパティ | 概要 |
|---|---|
| Hiragana | ひらがな |
| Katakana | カタカナ |
| Han | 漢字 |
| Punct | 句読点 |
| Digit | 数字(10進数) |
| Space | 空白 |
| Lower | 小文字英字 |
| Upper | 大文字英字 |
例:文字列からひらがな、カタカナ、漢字をそれぞれ取り出す
<?php
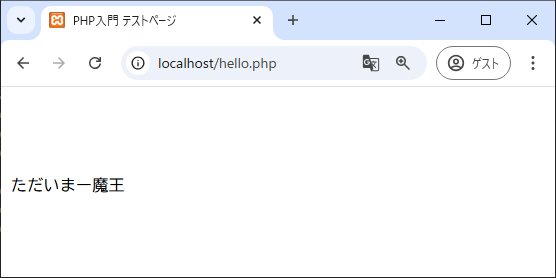
$str = 'ただいま魔王を倒せる勇者募集中ー!';
preg_match('/[\p{Hiragana}]+/u',$str,$data);
preg_match('/[\p{Katakana}ー]+/u',$str,$data2);
preg_match('/[\p{Han}]+/u',$str,$data3);
print $data[0];
print $data2[0];
print $data3[0];