SQL Serverがクライアントからのクエリを受け取ってから、データにアクセスするまでの内部的なステップ、いわゆるクエリのライフサイクルについて解説しています。また、クエリオプティマイザの処理の流れや統計情報の解説もしています。パフォーマンスチューニングに役立つかと思います。
SQLServer2022
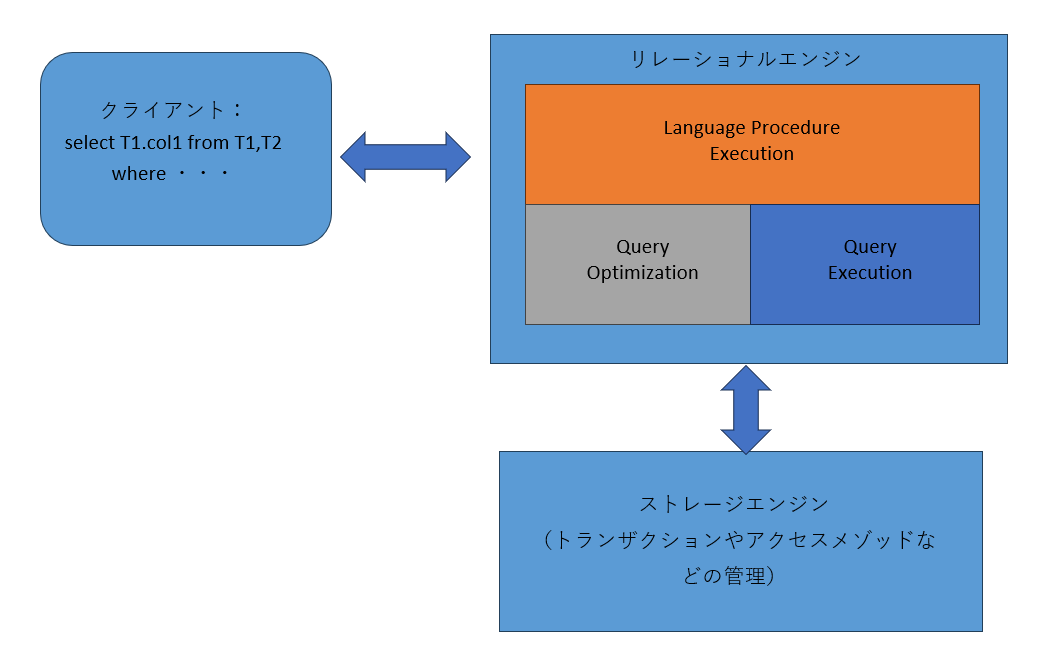
クエリが実行されるまでの一連の処理の流れや、その過程で決定されるデータアクセス方法は、クエリ実行時のパフォーマンスに大きな影響を与えます。この処理を行うコンポーネント群を「リレーショナルエンジン」もしくは「クエリプロセッサ」と呼びます。
リレーショナルエンジンの構成
リレーショナルエンジンは大きく分けて次の3つのコンポーネントで構成されています。それぞれのコンポーネントは、さらに多くのサブコンポーネントによって構成されています。(図1)
- Language Procedure Execution:クライアントから受け取ったクエリの構文解析や、クエリのパラメータ化などを行う。
- Query Optimization:クエリの最適化を行う
- Query Execution:クエリの処理に必要なリソースの獲得や、クエリの実行を行う。
クエリのライフサイクル
クライアントから受け取ったクエリの処理要求は、リレーショナルエンジン内で次のようなステップを経て実行されます。
図2
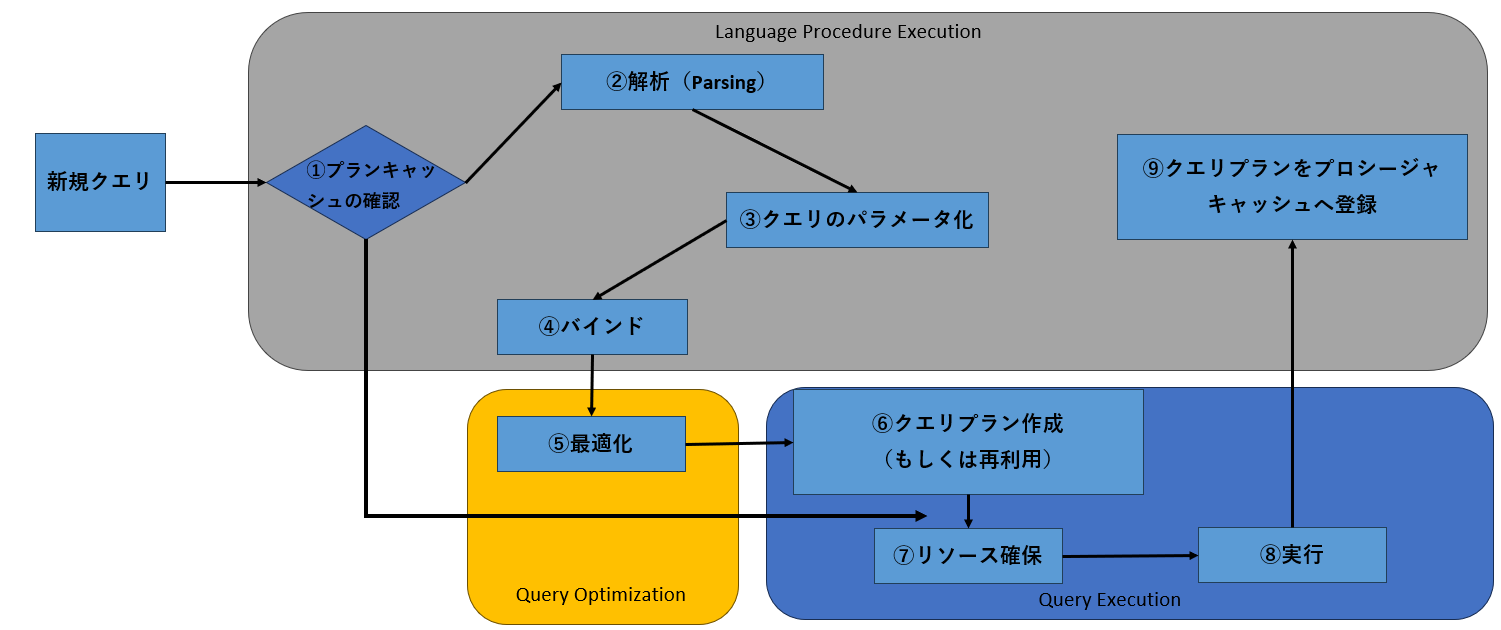
プランキャッシュの確認
プランキャッシュ(あるいはプロシージャキャッシュ)には、これまでに実行されたクエリの実行プランが一定期間格納されています。また、格納されたクエリナランは、クエリブラン生成の基となった実際のクエリテキスト(Selectステートメ
ントなど)も保持しています。
もしも、クライアントから受け取ったクエリが、すでにブランキャッシュに存在するクエリと合致する場合は、多大なコストを必要とする最適化などの処理を省くことができます。そのため、クライアントからクエリを受け取ったら、まずプランキャッシュに合致するものが存在するかを、クエリテキストの比較によって確認します。
解析(Parsing)
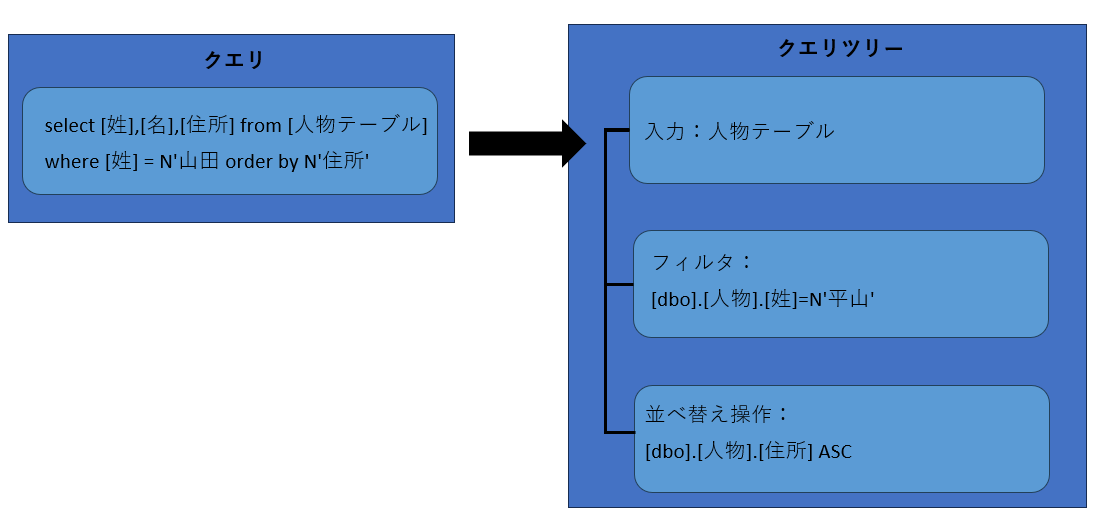
クライアントから受け取ったクエリの解析を行ないます。クエリの解析とは、クエリの構成要素を入力データソースとしてのテーブルや、入力データのフィルタリングとしてのwhere句、データの処理に影響を与えるorderbyオペレータなどにいったん分類し、それらをツリー構造に再構成することを意味します。再構成されたツリーは「クエリツリー(またはリレーショナルオペレータツリー)」と呼ばれ、その後のステップでクエリの最適化が行なわれる際に使用されます。(図3)
図3:クエリツリー
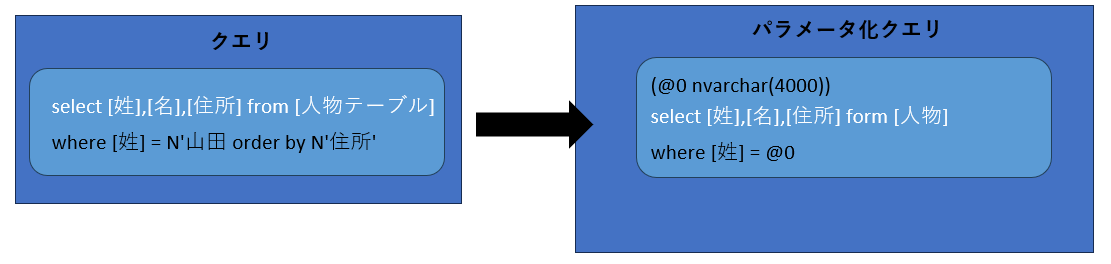
クエリのパラメータ化
将来的にクエリが再実行されることに備えて、プランキャッシュに格納するための準備を行ないます。具体的には、クライアントから受け取ったクエリテキストをパラメータ化クエリに変換します。
where句の条件がパラメータ化され、汎用性が高められた形で保存する
図4:パラメータ化クエリへの変換
バインド
クエリで操作されるテーブルなどの列と、クライアントへ返される結果セットのバインド(関連付け)が行なわれます。
最適化
クエリの解析結果として受け渡されたクエリツリーを基に、クエリオプティマイザによってクエリプランが生成されます。クエリオプティマイザの動作は、パフォーマンスチューニングの際にとても重要な意味を持つため、次節で詳細を説明します。
クエリプラン生成(もしくは再利用)
クエリプランがプランキャッシュに存在する場合は、再利用が行なわれます。存在しない場合は、クエリオプティマイザによって生成されたコンパイル済みプランを基に実行可能プランが生成されます。
リソース確保
クエリプランに基づいて、クエリを処理するために必要なリソースを確保します。例えば、結果セットの並べ替えが必要な場合は、並べ替え用のメモリの獲得を要求します。あるいは、並列で処理されるべきクエリには、並列処理に必要な内部スレッドの獲得要求を行ないます。
実行
クエリプランに基づいたリソースの確保が完了すると、クエリの実行が開始されます。
クエリオプティマイザ
SQL Serverが実装しているクエリオプティマイザのアルゴリズムは、GoetzGraefe氏によってIEEEの刊行物注で発表された。「Cascades」フレームワークを基本としています。Cascadesフレームワークについての仕様が掲載されたドキュメントは、現在もマイクロソフトのFTPサイト注3などからダウンロードできるので、興味のある方はぜひ参考にしてください。
クエリオプティマイザのアルゴリズムに同じくCascadesフレームワークを採用しているRDBMSとしては、旧タンデム社(現HP)のNonstopSQLが存在します(両者を結び付ける存在は、双方の開発に携わったJimGray氏注4と言えるのではないでしょうか)。
SQLServerにおけるクエリオプティマイザの役割は、「論理的」なクエリツリーをLanguageProcedureExecution(LPE)から受け取り、実行可能な「物理的」クエリツリーに変換して、クエリプロセッサへ受け渡すことです。その過程において、クエリは必要に応じて何段階にもわたって変換されます。ここでは、クエリオプティマイザが行なう処理の過程を記載します(図5)。
図5:クエリオプティマイザの処理ステップ
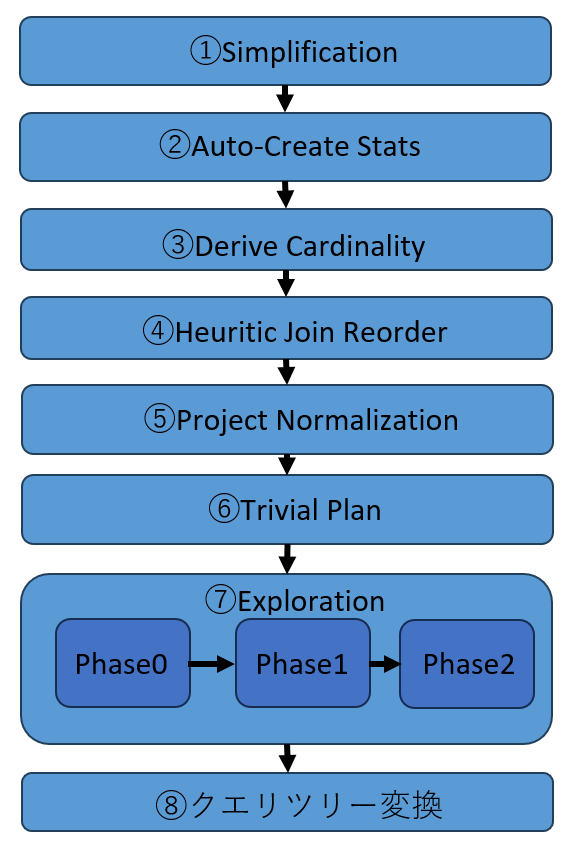
①Simplification
LPEから受け取った「論理的」クエリツリー内の入力テーブルを明確にしたり、重複箇所を取り除いたりして、ツリーの単純化、正規化を行います。
②Auto-Create Stats
クエリの実行に必要な統計情報が存在しない場合は、この段階で作成します。
③Derive Cardinality
統計情報のメモリへのロードが行われます。
④Heuristic Join Reorder
クエリがテーブルの結合を行っている場合に、クエリプランを検討する際の基本となる最初のテーブル結合順を決定します。クエリ内で同じテーブルが複数回結合されているような場合は、この段階で単純化されて、不要な結合は取り除かれます。
⑤Project Normalization
クエリに含まれる計算列などが、非決定的であるなどの理由によって、プラン生成の考慮に含まれない場合は、以降のTrivialPlanステップやExplorationステップ
で、プラン生成を行なう際に除外します。
⑥TrivialPlan
実行されるクエリや対象となるテーブルのスキーマが非常に単純な場合、この階でコストを考慮しないプラン生成が行なわれます。その結果として、生成可能なクエリプランの選択肢が1つしかない場合は、次のExplorationステップが省略され、この段階で生成されたクエリプランがクエリツリー変換ステップに受け渡されます。非常に単純なクエリとは、結合にも並べ替えなどが含まれないようなクエリのことです。例えば、次のようなクエリです。
select col from Tablel⑦Exploration
SQLServerのクエリオプティマイザの動作の中で、コストを基にプランを考慮する唯一のステップです。ほとんどのクエリは、Explorationステップの中のいずれかのフェーズで生成されたクエリプランを使用します。
PhaseO
並列プランは考慮しない、結合方式はNestedLoop注5のみを考慮するなどの条件下で、限定的なプランの検討を行ないます。そのような条件に当てはまらないようなクエリは、このフェーズをスキップして、次のPhase1からプランの検討を開始します。この段階で0.2よりも低いコストのクエリプランの生成が可能であった場合は、次のフェーズには進まずに、この段階で生成されたクエリプランがクエリツリ一変換ステップに受け渡されます。
Phase1
比較的使用頻度が高いクエリプランと、実行対象のクエリツリーのパターンが合致するかどうかを確認します。合致するパターンが確認できて、そのパターンを適用した場合のコストが10よりも低い場合は、次のフェーズには進まずに、この段階で生成されたクエリプランがクエリツリー変換ステップに受け渡されます。
Phase2
すべての可能性を検討して、実行対象クエリに特化したクエリプランの生成が検討されます。クエリオプティマイザに割り当てられた時間を超えてしまった場合は、プランの検討は打ち切られ、その段階で最も低いコストのクエリプランがクエリッリー変換ステップに受け渡されます。
6クエリツリー変換
TrivialPlanステップまたはExplorationステップから受け渡されたクエリプランを基に、「物理的」クエリツリーが生成されます。生成されたクエリツリーは、クエリの実行を制御するコンポーネントであるクエリプロセッサへ受け渡されます。
クエリオプティマイザとクエリプラン
SQLServerのクエリオプティマイザの動作に関して調べているとある資料から、次のような一文を目にしました。
SQLServerのオプティマイザはoptimal(最適)なクエリプランを生成するのではなく、制限時間内にreasonable(妥当)なクエリプランを生成することを目的とする。
最適なクエリプランを生成する最も確実な手段は、クエリで使用されているすべてのテーブルのデータの状況を把握し、すべてのテーブルのあらゆるインデックスの状況を把握し、テーブル結合順序、使用するインデックス、テーブル結合の種類などのすべての組み合わせパターンを比較した結果、最もコストが低いものを選択することです。
しかし、それらのすべてのパターンについて比較検討するのは、クエリに関与するテーブルの数やテーブルに作成されたインデックスの数が増えるにつれて、多くの時間を必要とするようになります。
時間を無尽蔵に使えるのならば、最適なクエリプランを生成するのに、そのような手順をとっても問題はありませんが、SQLServerにはクエリに対して速やかに結果セットを返すことが期待されています。例えば、次のような2つのレスポンスタイムの例について考えてみましょう。ほとんどの場合、ユーザーが求めるものは
2だと考えられます。
①最適なクエリプラン生成(10秒)+クエリ実行時間(1秒)=クライアントから見たレスポンスタイム(11秒)
②妥当なクエリプラン生成(2秒)+クエリ実行時間(2秒)=クライアントから見たレスポンスタイム(4秒)
クエリ実行時間を短くするために、クエリプランに必要以上に時間を要するのでは、本末転倒になってしまいます。そのため、SQLServerでは実行されるクエリの内容に応じて、クエリプランの生成に使用できる時間を自ら設定します。そして、その範囲内で妥当なクエリプランを生成することを使命としています。
統計情報
SQL Serverが実装しているのは、クエリプランを生成するときの評価基準としてコストを使用する、コストベースのオプティマイザです。そして、コストを算出する際にとても重要な意味を持つのが「統計情報」です。また、コストの算出に大きな影響を与えるのが、クエリ実行時の操作対象となる行数です。
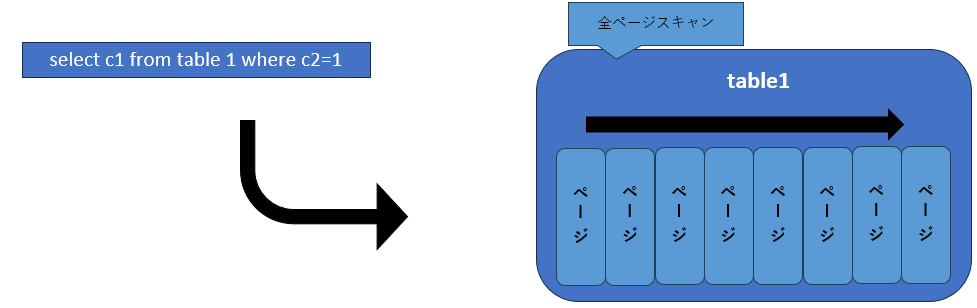
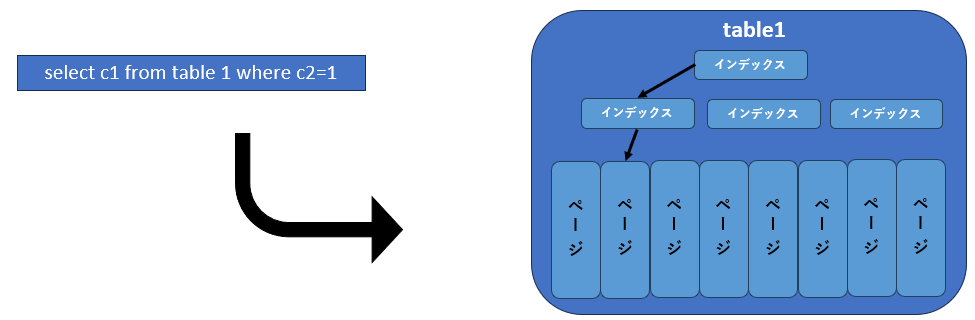
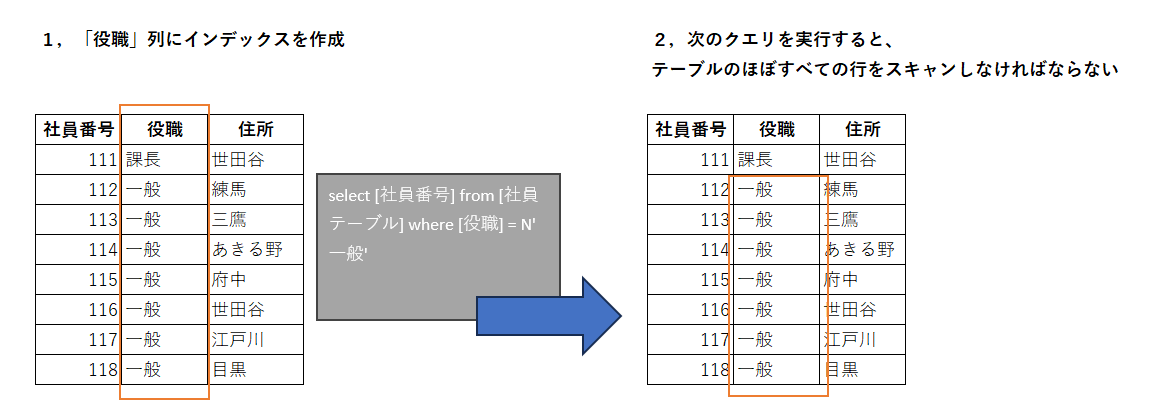
例えば、図6のように同じクエリを実行する場合でも、対象テーブルにインデックスが定義してあれば、とても少ない行を操作するだけで目的のデータに到達できます。しかし、インデックスが存在しない場合は、テーブル全体をスキャンしなければならず、操作する必要のあるデータ件数も多くなります。そのため、インデックスが定義されたテーブルのほうが低いコストで結果を得ることができます。
図6:クエリコスト
インデックスが存在しない場合は、テーブル全体を確認する必要があり、相当数のI/Oが必要になるためコストは高い
インデックスが存在する場合は、キー値によってアクセス範囲が絞り込めるため、I/O数は少なくコストは低い
では、インデックスが定義されている列の値が(図7)の場合はどうでしょうか。このようなデータ分布状況では、必要なデータを得るためには結局のところ、テーブル全体を検索する必要があり、必要なコストは図6のインデックスが存在しないテーブルと大差なくなってしまいます。
図7:選択性の低いインデックス
これらの例から明らかなことは、クエリで使用されている各列のデータ分布状況を考慮しなければ、コストの算出はできないという点です。そして、各列の値を実
際に確認しなくても、データの分布状況を把握するための仕組みが統計情報です。統計情報は、オプティマイザがクエリプランを生成する、ごく初期段階でメモリにロードされます。そしてその後、コストの算出が必要になった段階でその値が使用さ
れます。それでは、統計情報として格納されている各種情報について紹介します。
ヒストグラム(histogram)
「ヒストグラム」は統計学の用語で、度数分布を表わすための手法です。分析対象を一定の基準に基づいて分割し、それぞれの分割単位ごとに属するデータの数を保持します(図8)。
図8:ヒストグラム
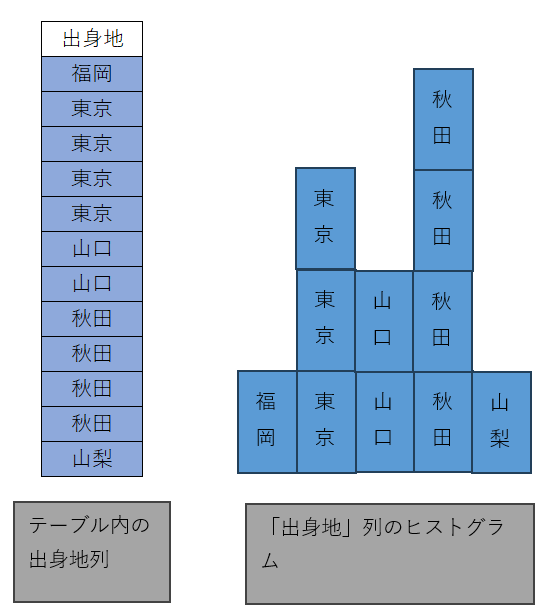
SQL Serverでは、統計情報は列やインデックスの状態を表わす際に使用されるため、その分析対象は列に含まれるデータになります。どのような状態でSQLServerが統計情報としてヒストグラムを格納しているかは、「統計情報の確認」の節で具体的に紹介します。
密度(density)
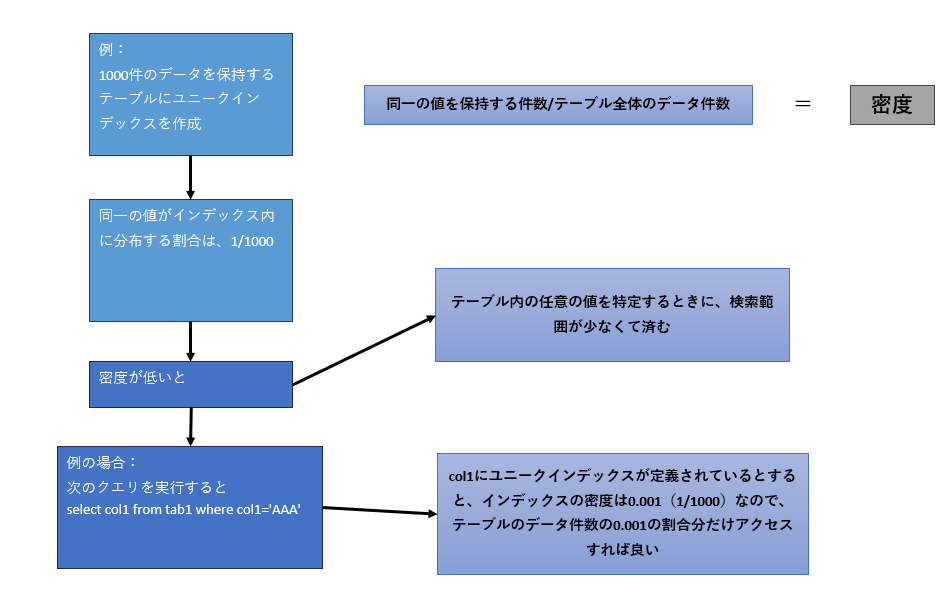
統計情報を保持する列が持つデータの一意性の状態に関する情報として、「密度」が格納されています。この情報は、特にインデックスの有効性(選択性:selectivity)を判断する際に使用されます。密度は次の式で求めることができます。
1 / 列が保持する一意の行数それでは、密度として示される値が高いほうが選択性は高いのでしょうか。あるいは、密度が低いほうが選択性は高いのでしょうか。ユニークインデックスとユニークではないインデックスを例に考えてみます。列Aにユニークインデックスが定義されているテーブルが、1000行のデータを保持しているとします。列Aに含まれるデータはすべて一意なので、インデックスの密度は1/1000、つまり0.001です。
一方、列Bにユニークではないインデックスが定義されているテーブルBが、1000行のデータを保持しているとします。また、列Bには3種類のデータ(例えば優先度を表わす「high」「middle」「low」といったコード)のみが同じ割合で含まれています。その場合の密度は1/3、つまり0.333です。
図9のようにクエリを実行すると、テーブルAのユニークインデックスを使用することで、データの検索対象は全件数の0.001(密度の値です)に絞ることができます。つまり、1件のみにアクセスすれば良いということになります。しかし、テーブルBのインデックスを使用すると、データのアクセス範囲は全件数の0.3なので、333件までしか絞り込むことができません。そのため、統計情報の密度が低いほど選択性が高く、アクセス範囲が絞り込めるということになります。
図9:密度で判断できること
一般的には、0.1以下の密度であれば、選択性は高いとされています。つまり、特定の値へアクセスするために必要な検索件数が、テーブル全体の1/10以下であれば、妥当なテーブルのデザインであるということになります。
その他
統計情報には次の情報も含まれます。
- 統計情報が作成された日付
- 統計情報を保持する列の平均データ長
- ヒストグラムと密度に関する情報を作成するために使用したサンプル数
サイズの大きなテーブルの場合、3番目の「サンプル数」が重要な意味を持つことがあります。統計情報を作成する際には、必ずしもテーブルが保持するすべてのデータを検証するわけではありません。テーブルが非常に大きな場合にすべてのデータを検証すると、統計情報の作成作業自体がシステムに大きな負荷を与え、スループットを低下させます。そのため、デフォルトではサンプル数は非常に低い割合に抑えられています。
図10:統計情報作成時のサンプル数
1,サンプル数の少ない場合
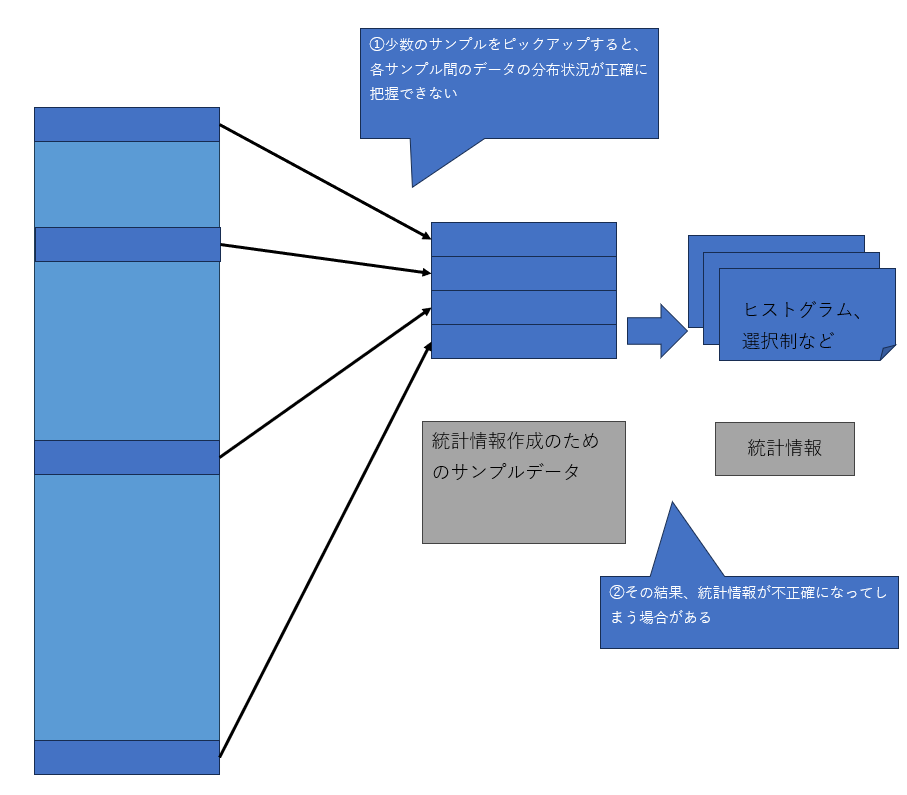
2,サンプル数が多い場合
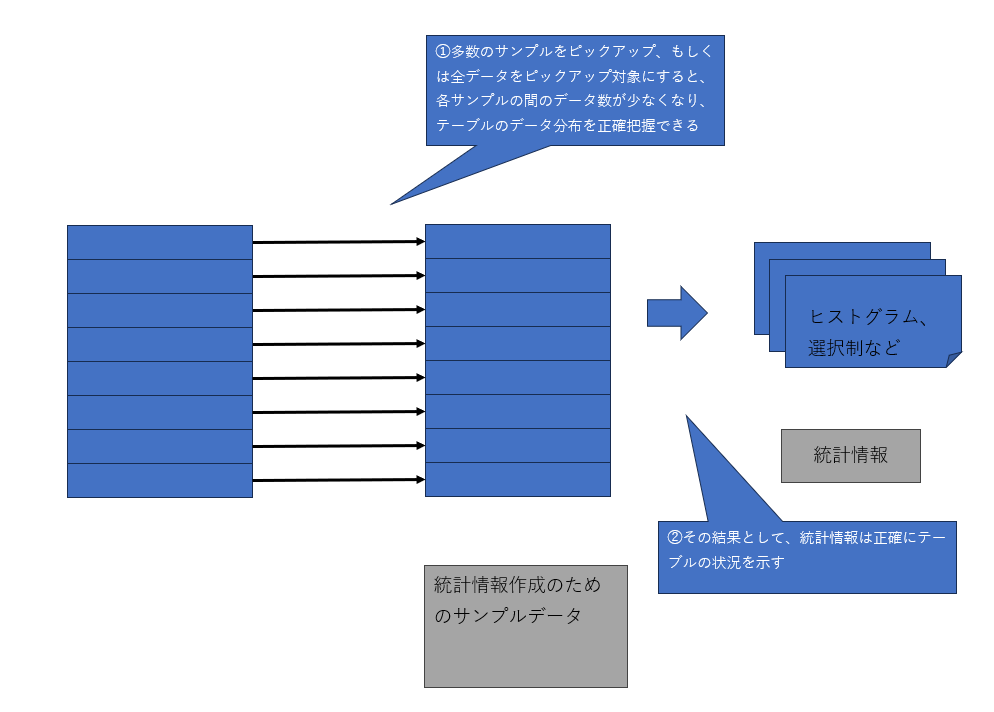
しかし、その低い割合が災いして、データ分布などの実態を正確に表わさない続計情報が作成されることがあります。そのような場合、効率的ではないクエリプランが生成される原因にもなり得ます。クエリプランが非効率的だと考えられる場合
や、意図したインデックスが使われないなどの問題がある場合は、関連する統計情
報のサンプル数を確認してください。テーブルの全体件数とサンプル数があまりにかけ離れている場合は、統計情報の作成時にテーブル全体をスキャンするように指定すると、それらの問題を回避できることがあります。具体的な手段を次の節で紹
介します。
統計情報が作成される契機
統計情報は、次の3つのいずれかのパターンで作成されます。
明示的に作成
次のT-SQLコマンドを実行することによって、任意の列の統計情報を作成できます。
create statistics 統計情報名 on テーブル名(列名)また、統計情報を作成する際に使用するサンプル行数は、次のように制御できます。
テーブル内の50%の行をサンプルとして使用する
create statistics 統計情報名 on テーブル名(列名) with sample 50 persentテーブル内のすべての行をサンプルとして使用する
create statistics 統計情報名 on テーブル名(列名) with fullscan自動作成プロパティ
データベースの統計情報自動作成プロパティが有効化されている場合、クエリ実行時に必要な統計情報が存在しないと自動的に作成されます。
統計情報自動作成プロパティの有効化(デフォルト設定では有効)
alter database データベース名 set AUTO_CREATE_STATISTICSON統計情報自動作成プロパティの無効化
alter database データベース名 set AUTO_CREATE_STATISTICSOFFインデックス作成時に作成
すでにデータ格納されているテーブルに対してインデックスを作成すると、インデックスに使用された列に関する統計情報が作成されます。
統計情報の確認
統計情報に格納されている内容を確認するには次のコマンドを実行します。
dbcc show_statistics(テーブル名,統計情報名)このコマンドを実行すると、「ヘッダー情報」「密度情報」「ヒストグラム」の各項目が出力されます。ここでは、以下のサンプルテーブルを使用します。
--サンプルテーブル定義
create table 人物 (姓 nvarchar(50),名 nvarchar(50),住所 nvarchar(50))
go
--データのインサート
insert 人物 values(N'ひらやま',N'おさむ',N'東京')
insert 人物 values(N'ひらやま',N'おさむ',N'東京')
insert 人物 values(N'あかさか',N'たろう',N'秋田')
insert 人物 values(N'かにやま',N'たろう',N'福島')
insert 人物 values(N'さとう',N'こうた',N'山口')
insert 人物 values(N'ながの',N'まもる',N'和歌山')
go
-- インデックスの作成
create index 索引氏名 on 人物(姓,名)
go
このサンプルテーブルは、明示的に統計情報を作成したわけではありませんが、データが格納された後でインデックスを作成したので、インデックスで使用されている列に対する統計情報が作成されています。次のコマンドを実行して内容を確認します。
dbcc show_statistics(人物,索引氏名)図11
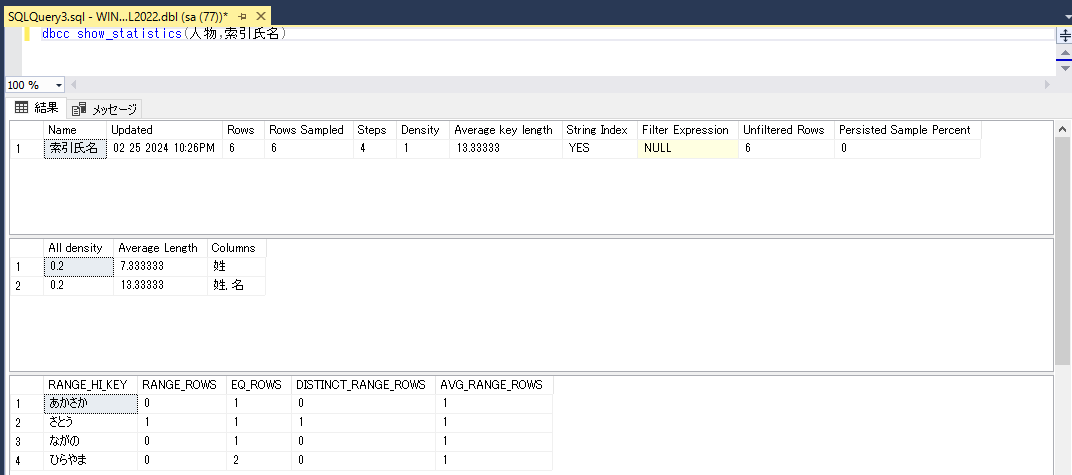
ヘッダー情報
統計情報名(インデックス作成時に作成されたものはインデックスと同じ名前です)、統計情報の最終更新日、テーブルの行数、統計情報作成時に使用されたサンプル行数などの情報が出力されます。
今回のサンプルは6件のデータをインサートしたため、「Rows」に6という値が示されています。また、「RowsSampled」にはサンプルとして使用したデータ件数である6が示されています(LIST2)。
図:LIST2

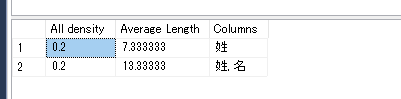
密度情報
列の密度(density)情報が出力されます。統計情報が複数の列で構成される場合は、列を組み合わせた場合の密度も含まれます。今回の場合は、「姓」のみのバ「ターンと「姓」「名」が組み合わされたパターンの情報が存在します。一般的には複数の行が組み合わされた場合の密度は低い傾向にありますが、今回はデータ数が少ないために、変化がありませんでした(LIST3)。
図:LIST3
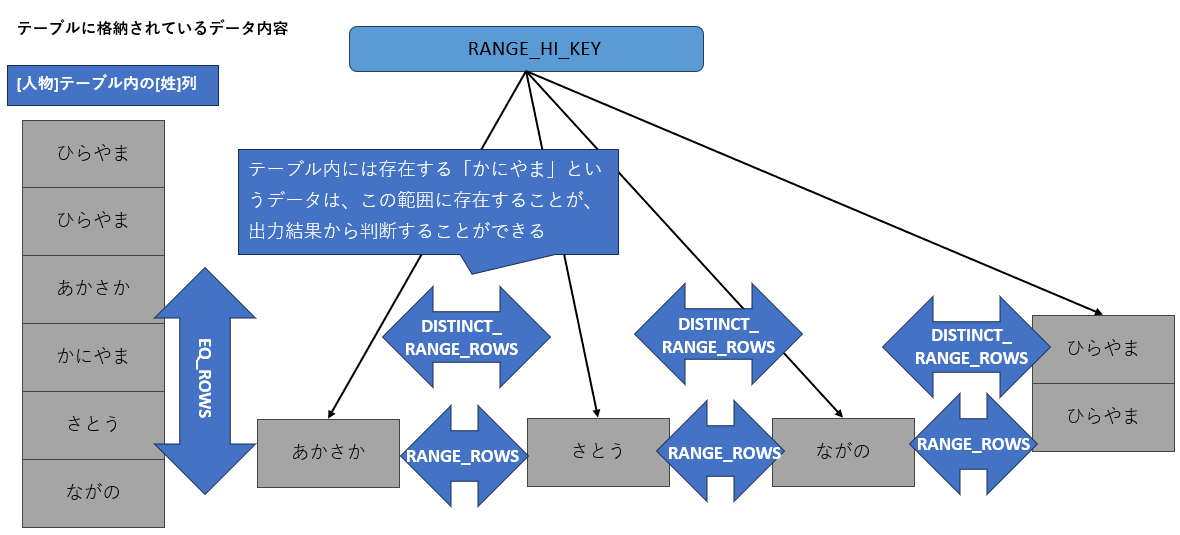
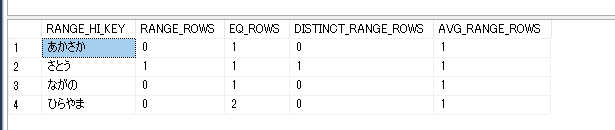
ヒストグラム
データの分布状況は、表の項目を使用して表現されています。今回のサンプルでは、LIST4のように出力されました。
| RANGE_HI_KEY | ステップの上限キー値 |
| RANGE_ROWS | ステップ範囲内の行数。RANGE_HI_KEYは含まない |
| EQ_ROWS | RANGE_HI_KEYとまったく同じ値の行数 |
| AVG_RANGE_ROWS | ステップ範囲内の一意な値ごとの平均行数 |
| DISTINCT_RANGE_ROWS | ステップ範囲内の一意なキー値の数。RANGE_HI_KEYは含まない |
図:LIST4
この情報基にSQLServerはデータの分布状況を推測します(図11)。LIST4の結果を以下に図解しました。
図11:サンプルテーブルとヒストグラム