
ちょっと、古い内容になりますが、SQLServerのデータファイル(ページとエクステント)、ログファイル、トランザクションログ構造、データベースファイルの管理方法とデータ効率的な格納方法についてわかりやすく解説しています。SQLServerが管理するデータベースは、少なくても1つのデータファイルと、1つのログファイルで構成されています。もちろん複数のデータファイルとログファイルで構成することも可能です。1つ目のデータファイルは、デフォルトでは拡張子が.mdfとして設定され、データベースの管理に必要なシステムオブジェクトが格納されています。それでは、データファイルとログファイルについてわかりやすく解説しています。
データファイル
ページとエクステント
データベースのデータファイルが「ページ」と呼ばれる8KBの論理単位に区切って使用されています。ページはテーブルなどのオブジェクトに格納されたデータを参照したり、更新したりする場合のI/Oの最小単位として使用されます。ただし、オブジェクトに新たな領域を割り当てる必要がある場合には、ページではなく「エクステント」と呼ばれる単位が使用されます。エクステントは8KBのページが8個で構成されています。例えば、テーブルに割り当てられたすべてのページに空きがなくなると、テーブルには新たなエクステントが割り当てられます(図1)。
図1
単ーエクステントと混合エクステント
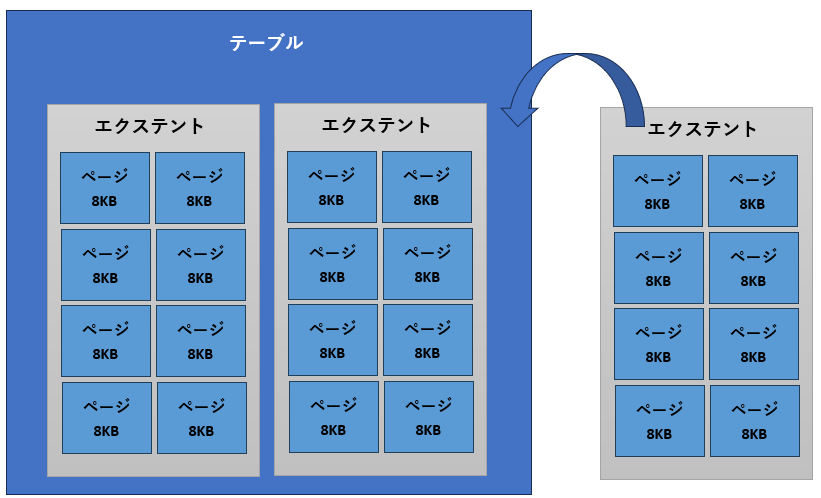
エクステントには、1つのオブジェクトに占有される単一エクステントと、複数のオブジェクトで共有される混合エクステントの2種類が存在します。どちらのエクステントを使用するかはSQL Serverによって決められます(ユーザーの自由にはなりません)。
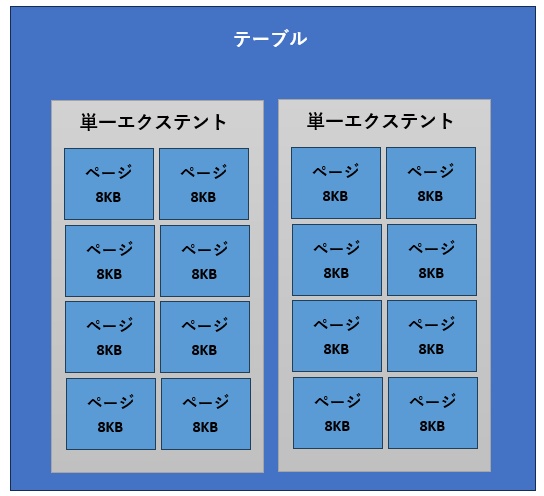
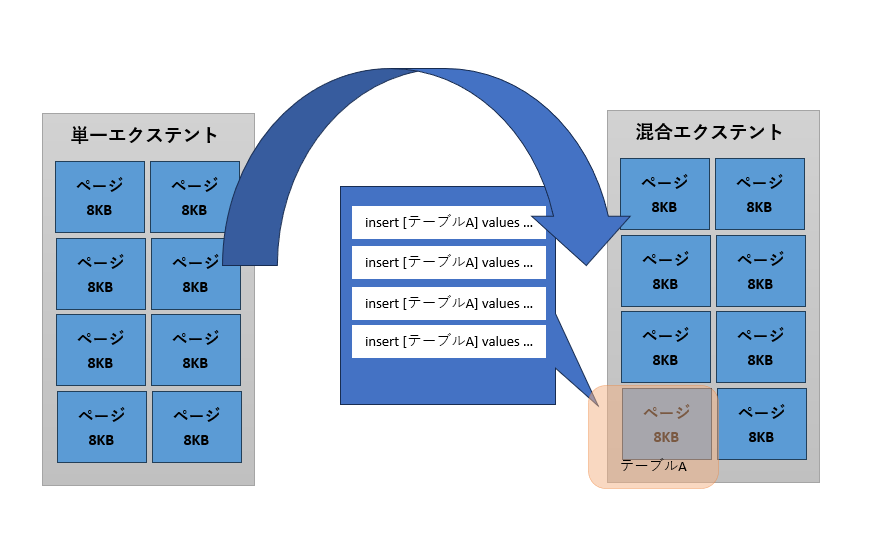
小さなサイズのオブジェクトは混合エクステントに割り当てられ、大きなサイズのものは単一エクステントへ割り当てられます。これはなぜでしょうか。もしも、1ページ以下の小さなサイズのテーブルに単一エクステントを割り当てると、ほかのオブジェクトが同じエクステントを使えなくなります。その結果、残りの7ページ(56KB)は使用されずに無駄になってしまい、ディスクを有効に活用できません。そのため、小さなテーブルには、ほかのオブジェクトと領域を共有できる混合エクステントが割り当てられます(図2)。
単一エクステントではすべてのページが同じオブジェクトに属する。すべての単一エクステントはテーブルに所属
図2
混合エクステントではエクステント内のページが複数のオブジェクトに属する
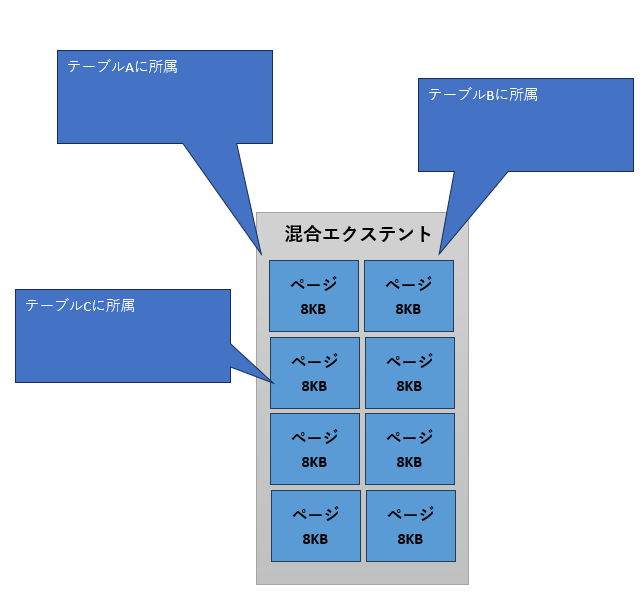
それではSQL Serverは、小さなサイズのオブジェクトと大きなサイズのオブジェクトを、どのようにして見分けているのでしょうか。すでに大きなサイズとなっているテーブルに関して判断するのは簡単ですが、作成された直後のオブジェクトが、この先大きくなるのか、それとも小さいままなのかを見極めるのは難しそうです。実は、これはSQLServerにも判断できません。そのため、まずは作成直後のオブジェクトを混合エクステントに割り当てます。その後、オブジェクトのサイズが1ページを超えると、単一エクステントを割り当てるようにしています(図3)。
テーブル作成時は、まず混合エクステントにページが割り当てられる
図3
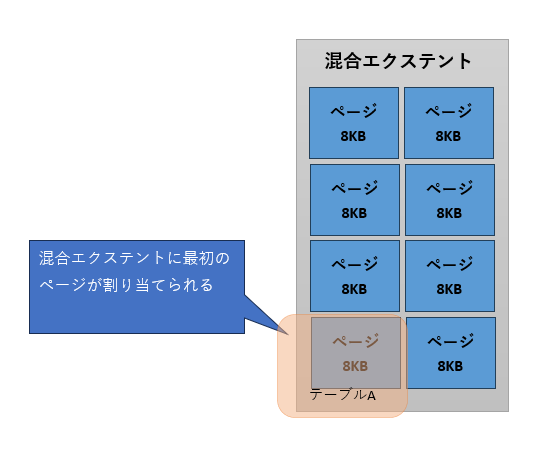
データが追加され1ページの範囲を超える
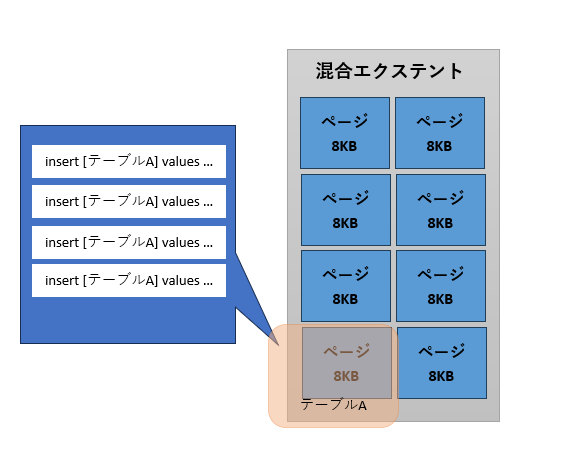
テーブルAに単一エクステントが割り当てられる
ページの種類
データファイル内のページは、次のうちのどれかを格納する用途で使用されています。
- IN_ROW_DATA:データまたはインデックスを格納
- LOB_DATA:ラージオブジェクト(text、ntext、image、xml、varchar(max)、nvarchar(max)、varbinary(max))を格納
- ROW_OVERFLOW_DATA:ページ上限の8KBを超えた可変長カラムのデータを格納(図4)
図4
1,テーブルA(col1 int型、col2 varchar(2000))
※ヘッダー除く

2,varcharカラムをより大きなサイズのデータで更新updateテーブルA set col2 = 2000バイト分のデータ

3,オーバーフローしが発生したデータはROW_OVERFLOW_DATAとして別ページに格納元のページにポインタが格納される。
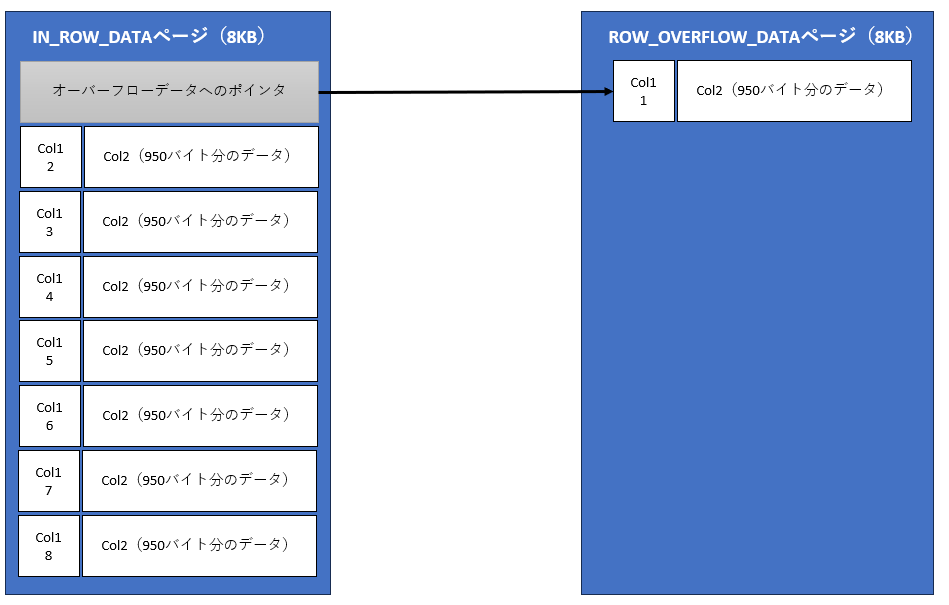
3,オーバーフローしが発生したデータはROW_OVERFLOW_DATAとして別ページに格納元のページにポインタが格納される。
ページの配置
データベース内のほとんどのページはデータやインデックスキーを格納することに使用されていますが、ごく少数の管理情報のみを格納したページが存在します。それらは、データベースを効率良く管理するためにデータベースの割り当て情報を保持しています。ここでは、それらの役割や格納している情報を説明します。
GAM(GlobalAllocationMap)
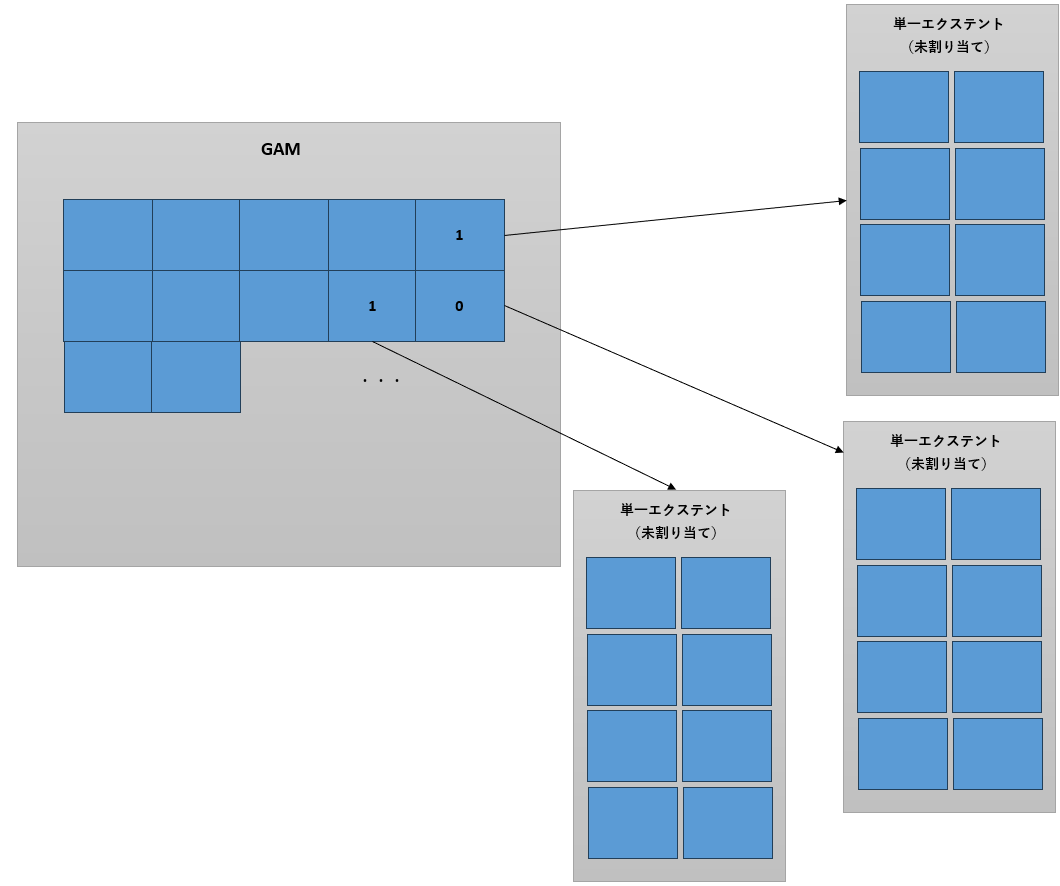
8KBのページの各ビットがエクステントの状況を示しています。もしもビットの値が1を示す場合は、対応するデータベース内のエクステントが単一エクステントとして割り当てられていないことを表わします。単一エクステントに割り当てられると、ビットの値は0に設定されます(図5)。1個のGAMページで64000エクステン
ト分(4GB)の状態を管理できます。SQLServerがオブジェクトへエクステントを新たに割り当てる場合には、このページを参照することによって、とてもシンプルに未使用のエクステントを見つけることができます。
GAM内の1ビットが各エクステントの使用状況を示す
図5
SGAM(SharedGlobalAllocationMap)
こちらは混合エクステントの状況を示しているページです。GAMと同様に8KB分の各ビットが対応するエクステントの状況を示しています。1が設定されている場合は、混合エクステントとして割り当てられていて空きページが存在することを示しています。0の場合は、空きページが存在しないか、混合エクステントとして割り当てられていないことを表わします(図6)。
SGAM内の1ビットが各エクステントの使用状況を示す
図6
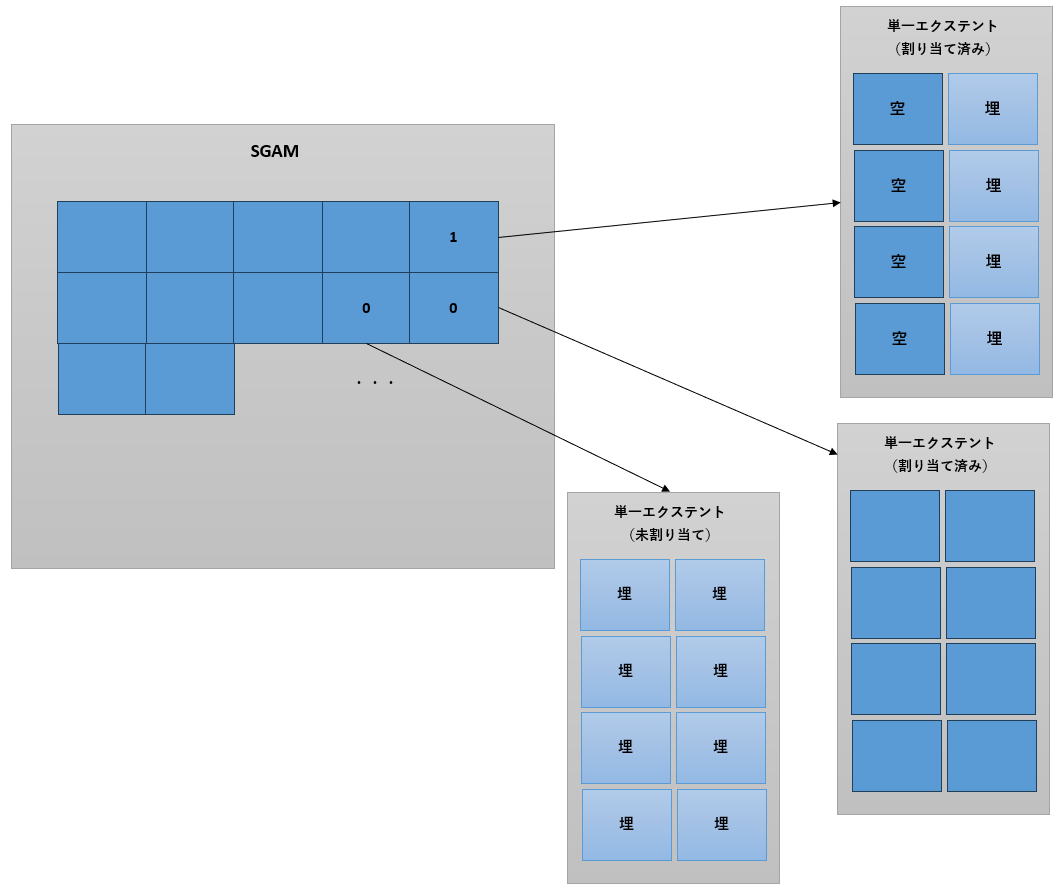
PFS(Page Free Space)
8KBのページの各バイトがそれぞれ対応するページの状況を示し、8000ページ分の情報を格納します。ページの使用済み/未使用といった情報に加えて、ページ使用率(0、1~50、51~80、81~95、96~100%)も確認できます。(図7)PFSの情報を使用して、新たなデータを格納するためのページを探します。ただし、インデックスページは、インデックスキー値によって格納すべき場所が決まります。そのため、PFSはヒープ(クラスタ化インデックスが作成されていないテーブルのデータページ)やText/Imageデータの格納場所探索のためにのみ使用されます。
図7
PFS内の1バイトが各ページの使用状況を示す
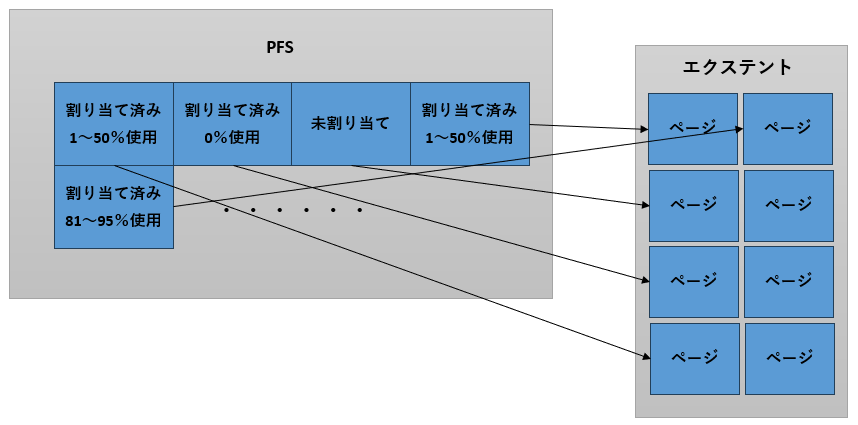
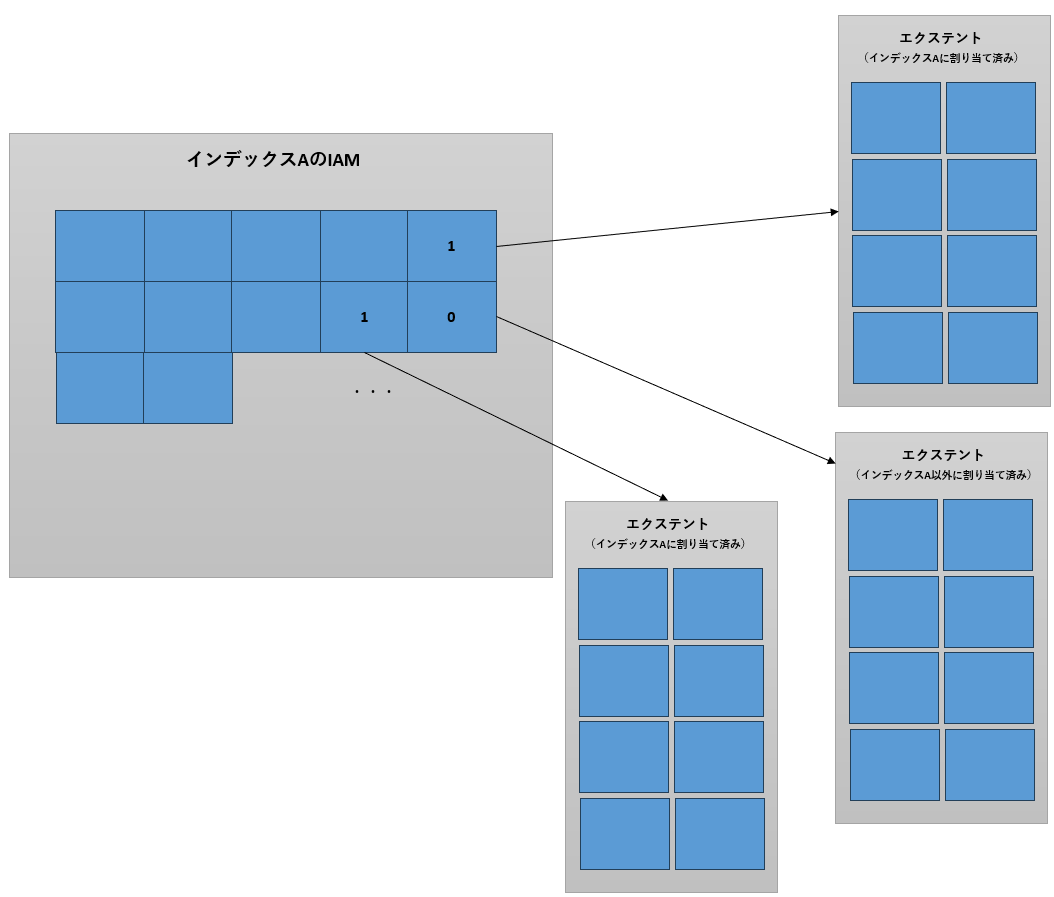
IAM(Index Allocation Map)
クラスタ化インデックス、非クラスタ化インデックス及びヒープと、それぞれのオブジェクトに使用されているエクステントを結び付けるために使用される8KBのページです。(図8)1個のIAMで64000エクステント分(4GB)の情報を管理することができます。インデックスなどのサイズが4GBを超える場合は、2個目のIAMが割り当てられます。双方のIAMはお互いのリンク情報を保持しています。
IAMの1ビットが各エクステントの状況を示す
インデックス/ヒープに割り当てられているエクステントに対応するビットに1が設定される
図8
ログファイル
トランザクションログの構造
トランザクションログは、SQLServerが管理するオブジェクトとしては例外的に8KBというページ単位が使用されません。トランザクションログレコードのサイズは、実行されたオペレーションによって4~60KBの範囲で変化します。
仮想ログファイル
SQLServerは、ログファイルの中をさらに複数のログファイルに分割して使用します。各仮想ログファイルを最小単位として、「使用中」「未使用」といったステータスが管理されます。また、ログファイルのシュリンクや拡張なども仮想ログファイルを1つの単位として実行されます。
仮想ログファイルのサイズはSQLServerによって決定されるため、ユーザーが直接的に関与することはできません。一般的には、データベースを作成した段階で小さなファイルサイズを指定すると、小さなサイズの仮想ログファイルが割り当てられます。反対に大きなサイズのログファイルは大きなサイズの仮想ログファイルに分割されます。小さな仮想ログファイルとして分割されたログファイルにトランザクションログが蓄積されていき、その結果として拡張が繰り返されたとします。結果的にログファイルはとても多くの数の(小さなサイズの)仮想ログファイルで構成されます。
SQLServerは多数の仮想ログファイルの管理(ステータスのアップデートなど)が必要となり、そのオーバーヘッドはパフォーマンスに悪影響を与える場合があります。そのような状況を避けるため、データベースを定義する段階で、必要最大限と考えられるサイズをトランザクションログファイルへ割り当てることをお勧めします。
データベースファイル内でのアクセス手法
データベース内の各オブジェクトへのアクセス手段は、「クエリオプティマイザ」と呼ばれるコンポーネントが決定します(クエリオプティマイザの動作については第9章で取り上げます)。
オプティマイザによって、最も効率的にデータにアクセスするための手段(最適なインデックスの選択など)を決定し、その決定に基づいた手順でテーブルなどに格納されたデータを取得します。クエリオプティマイザの動作自体も非常に興味深いものなのですが、ここではまずクエリオプティマイザがデータへのアクセス手段を決定した後で、どのようなアルゴリズムで実際のデータを取得しているのかを紹介します。
インデックスが使用される場合
各インデックスページは、同一階層の前ページと次ページのポインタをそれぞれ保持しています。また、インデックスの各階層もリンクリストで結び付けられています。そのため、例えば目的のデータを取得するためにインデックスをスキャンする必要がある場合、とてもシンプルなアルゴリズムでデータを取得できます。
スキャンの開始ページを、インデックスページ階層の上位から下位へリンクリストを使用して特定します。次に、前ページもしくは次ページのポインタを使用して、スキャンの開始からスキャン終了点まで移動しながら、データを取得すれば良いということになります。(図9)
1,下位ページID リンクチェーンを使用してリーフページに到達
図9
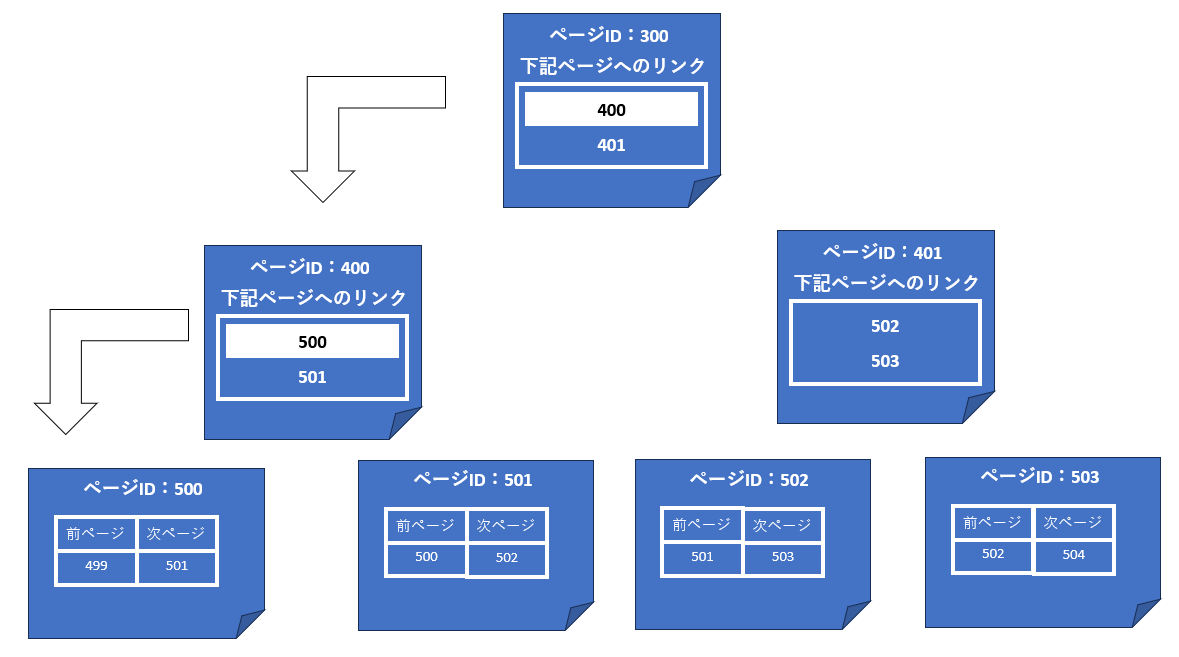
2,前ページ/次ページリンクチェーンを使用してリーフページをスキャン
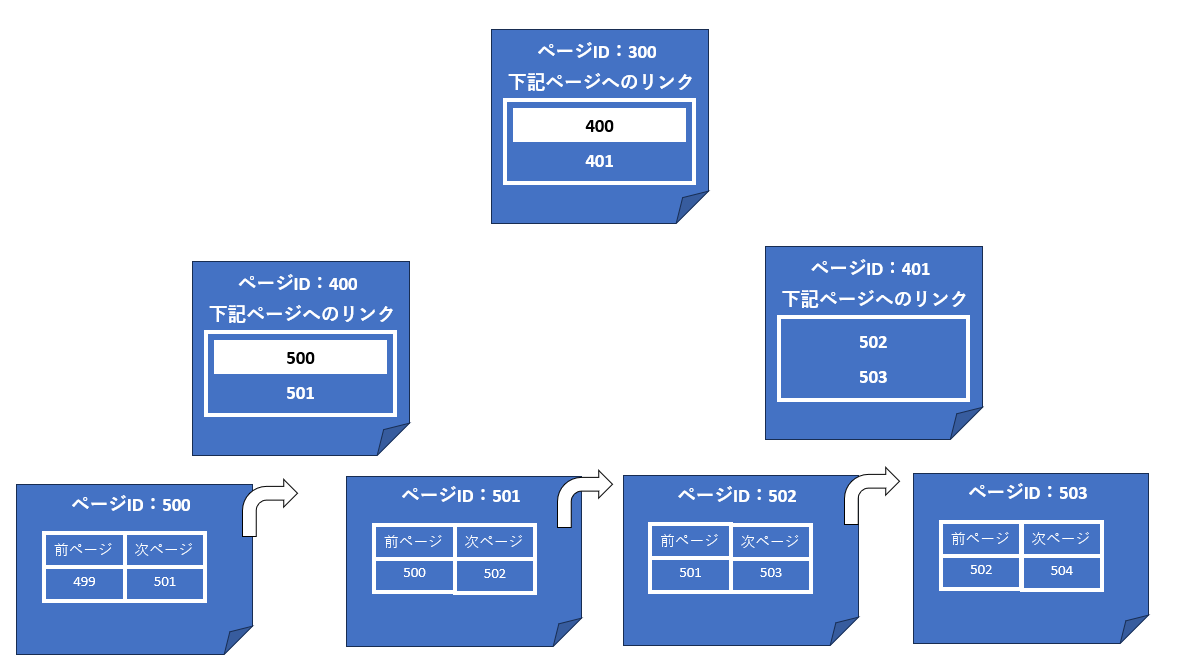
インデックスが使用されない場合
ヒーブテーブルの各データページは、前ページおよび次ページのポインタを保持
していません。そのため、個別のデータページだけではお互いの関連性がまったく把握できません(図10)。それでは、そのような状況でテーブル内の全件をスキャンする必要がある場合、どのような手順が考えられるでしょうか。
各ページの前ページ/次ページ情報に0が格納されている(ページ間の関連をたどれない)
図10

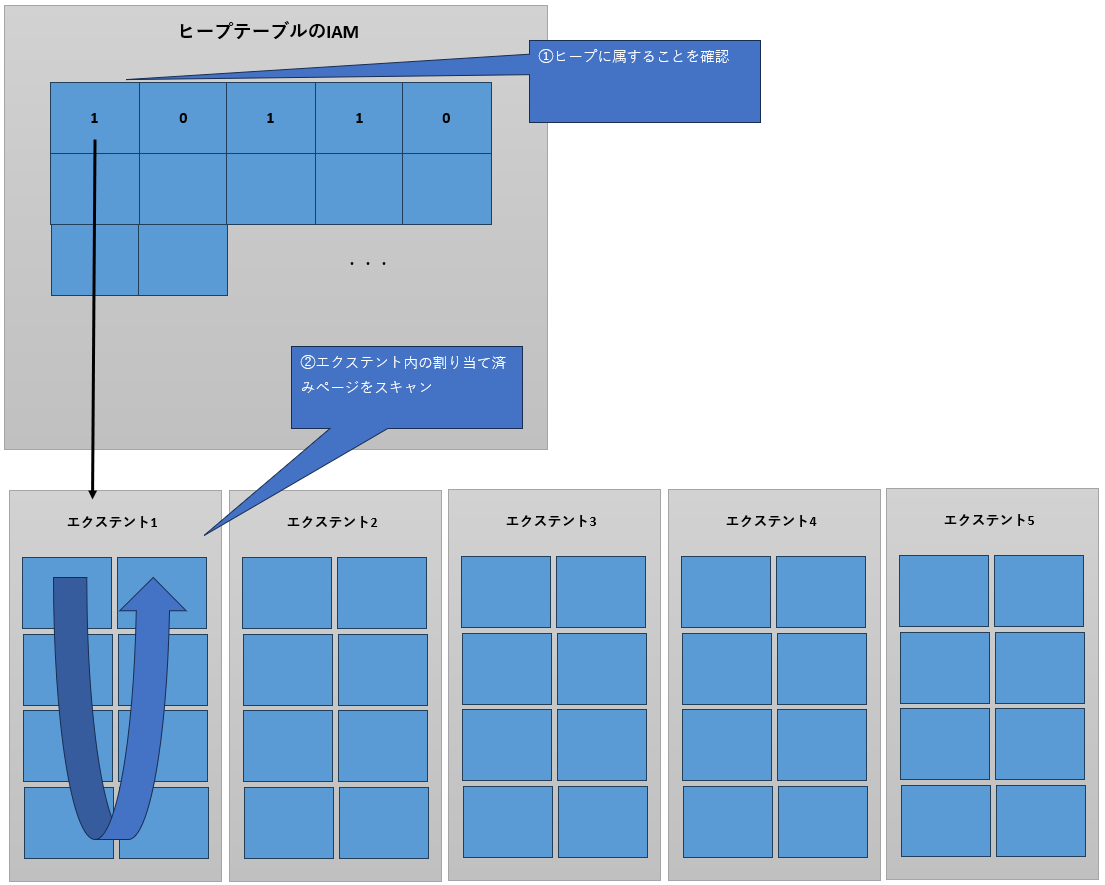
ヒープを構成している各データページには情報が保持されていないので、管理情報を格納しているページを頼りにするしか手段はありません。この場合は、前述のIAMが効果を発揮します。IAMの各ビットを確認することによって、ヒープが使用しているすべてのエクステントが明らかになります。あとは各エクステントに格納されているデータページを順次参照して、エクステント内のページをスキャンします。1つのエクステント内のすべてのページのスキャンが終了すると、IAMの情報に基づいて次のエクステントへ移動し、各データページへアクセスする、という動作の繰り返しによってヒーブテーブルをスキャンすることが可能になります(図11)。
1,IAMのビットがTrue(1)に設定されているエクステント内のページをスキャン
図11
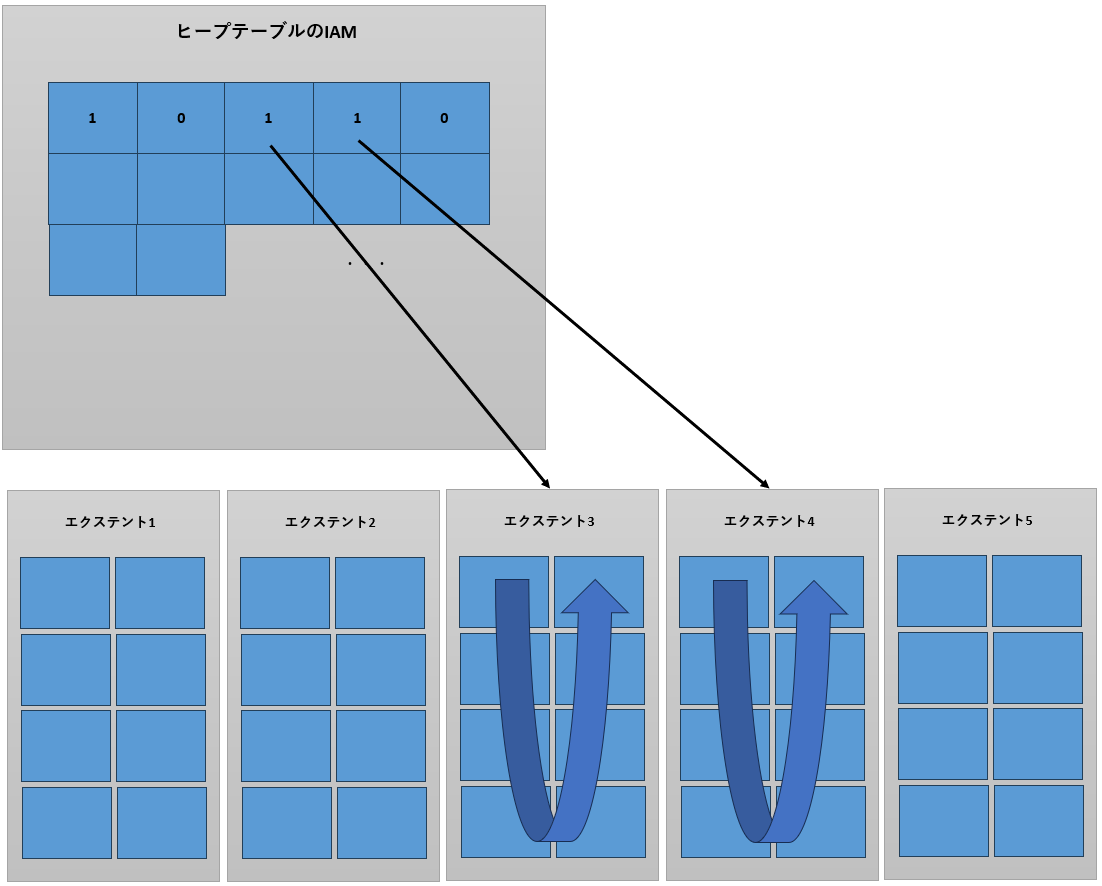
2,IAMのすべてのビットを確認して、True(1)に設定されている
エクステント内のページスキャンを繰り返す
データベースファイルの管理
データベースファイルには、管理を容易にするために用意された数多くのプロバティを設定できます。プロパティ群の中で最も一般的なものの1つとして、「自動拡張」があります。データファイルやログファイルがいっぱいになってしまった際に、自動的にファイルサイズを拡張してくれる便利な機能ですが、設定内容によっては思わぬトラブルを招く場合があるため、ここで紹介します。
原因不明のデータベース拡張失敗
データベースの各ファイルの自動拡張プロパティをデフォルトのままの設定にして運用を続けた結果、ディスクの空き容量は十分あるのに、次のようなエラーが発生して対処に困る場合があります。
エラー:1105 重大度レベル17 メッセージ:"Default'ファイルグループがいっぱいなので、データベース'db1'にオブジェクトtablelの領域を割り当てられませんでした。
実はデータベースの各ファイルを自動拡張する処理には、内部的にタイムアウト値が設定されています。その値は30秒となっていて、変更はできません。さらに、実際にディスクの空き容量が足りずにファイルの自動拡張が失敗した場合も、空き容量が十分に残っているにもかかわらずタイムアウトが発生した場合も、同じエラーが返されます(出力されるメッセージにも改善の余地がありますね)。
また、この問題は、ある時点までは問題なく運用できていたのに、突然問題が発生するようになる傾向があります。これはデータベースの各ファイルの拡張サイズの設定に原因があります。デフォルト設定では、ファイルの拡張サイズは「10%」になっています。100MBのデータファイルが容量不足によって拡張される際には、10MBが追加されます。
そのような小さなサイズの場合は、「10%」という値は一見無害に見えますが、例えば拡張が重なって50GBに到達したデータベースファイルではどうでしょうか。50GBの10%と言えば5GBです。ディスクの速度にもよりますが、5GBのファイル拡張を30秒以内で完了するのは、ほとんどの場合には失敗します。そのため、ドライブに100GBの空き容量があっても、拡張失敗のメッセージが返される結果になります。
SQLServer2005からの改善点
データベースファイル拡張に関して、SQLServer2005からはいくつかの点が改善されました。
●「ゼロ埋め」の回避
SQLServer2000までは、データベースを作成するときにも、データベースを拡張するときにも、必ずデータベースファイル内をゼロで埋めてフォーマットしていました。この動作は「ゼロ埋め(Zeroing)」と呼ばれています(図12)。当然のことながらゼロ埋めは、ファイルのサイズが大きくなればなるほど長い時間を必要とします。SQLServer2005からはサービス起動アカウントに、SE_MANAGE_VOLUME_NAME特権を与えることによって、ゼロ埋めを回避できるようになりました。これによりファイル拡張処理のパフォーマンスが飛躍的に向上しました。
●デフォルト設定の見直し
SQLServer2000までは「10%」に設定されていたファイルの自動拡張プロパテが見直され、「10MB」に変更されました。これによって、自動拡張プロパティに注意を払わないユーザーが不意に空き容量不足のエラーに直面しなくなります。
●理想的な設定
データファイル拡張失敗への、いくつかの対処がSQLServer2005で導入されていますが、実際の運用環境で日常的にデータファイルの自動拡張が頻繁に発生する
ことは望ましくありません。自動拡張が繰り返される背景には、データベースに追加されるデータの増加率などが正しく把握されていないことが多く、それはシステムの安定運用を脅かす要因になることがあります。そのため、常にシステムが必要なファイル容量を正確に把握するようにし、ファイル拡張が必要な場合は計画的に手動で実行することが理想です。自動拡張は、あくまで緊急避難的に使用することをお勧めします。
データの効率的な格納方法
一般的に、データベースに蓄積されるデータは日々増加していきます。増加するデータへの根本的な対処には、データの運用方針の確立や古いデータのアーカイブなどが不可欠です。しかしながら、そういった対処の必要性をできるだけ低くするために、効率的なデータ格納方法がSQLServer2005以降で順次実装されていきます。
NTFSファイル圧縮の使用
SQLServer2005から、データベースファイルの中で読み取り専用に設定されたファイルグループを、NTFSファイルに圧縮することがサポートされました。NTFSファイル圧縮を実行するには、エクスプローラやcompactコマンドを使用します。ただし、次の注意点があります。
●圧縮するファイルグループには「読み取り専用(READ_ONLY)」プロパティを設定する必要がある
●プライマリファイルグループ(.mdfファイルが含まれている)とログファイルは圧縮できない
●ただし、読み取り専用データベースではプライマリファイルグループも圧縮できる
vardecimal型
vardecimal型は、decimal型の格納領域をより有効に使用するために、SQLServer2005SP2以降で実装された機能です。decimal型列は、すべての行でテーブルの定義時に設定された領域を確保します。しかし、格納される数値には大きくばらつきがある場合も多く、10桁分を用意している場合であっても、行全体のうち8割以上が5桁以下ということも少なくありません。
もしもテーブルのサイズが巨大になった場合、使用されない桁数分を割り当てずに済むならば、大幅にディスク使用量を削減することができます。そのような場合にvardecimal型はとても有効です。vardecimal型を使用すると、実際の値に加えて2バイトのみが使用されます。これにより、効率的な実数データの格納が可能になります。使用にあたっては次の点に注意が必要です。
●EnterpriseDeveloper,Evaluationの各エディションで使用可能
●データ型としてテーブル定義時に指定するのではなく、データベースのプロパティとして設定する
●CPUの使用率が増加する可能性がある
システムデータベース(master,msdb,modeltempdb)にはvardecimalは設定できない
データ圧縮
SQLServer2008では、テーブルごとにデータを圧縮することが可能です。テーブル内のページ単位あるいは行単位で、データを圧縮することができます。これによって、必要となるストレージのサイズを節約できるとともに、I/O数の削減につながりパフォーマンスの向上も期待できます。
バックアップ圧縮
SQLServer2008では、データベースのバックアップを取得する際に、バックアップファイルを圧縮することができます。これによって、バックアップファイルのサイズの縮小、およびI/O数の削減によるバックアップ/復元時間の短縮につながります。
