
「MSQL Server 2014」を運用をしていた時に、突然バッチが遅くなり解析してみたら、SQLパフォーマンスが大分悪くなっていたので、その時の事例と解決方法を記載している。
事象
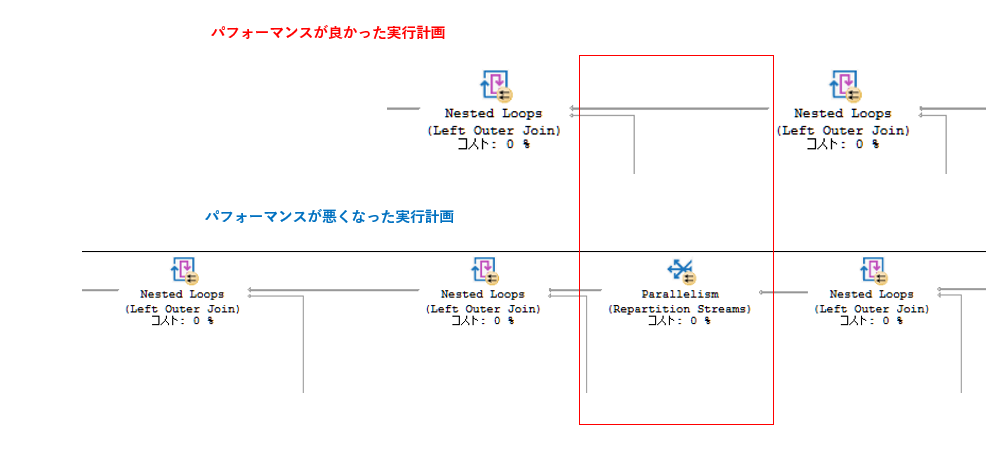
サブクエリ(副問い合わせ)でデータを集計(SUM)、LEFT JOINで他テーブルを結合したSQLが「Nested Loops」となっていてパフォーマンスが遅くなった。
高速だった時点と遅くなった時点の実行計画(プラン)を比較してみたところ、外部と内部テーブル結合に対して並列処理(Repartition Streams)が行われなくなっており、外部テーブルと内部テーブルの結合に「Nested Loops」を処理をしている。通常であれば2分程度で終わるクエリが1時間以上レスポンスがないくらいSQLパフォーマンスが悪い。
実行計画は、「Microsoft SQL Server Management Studio」の以下のアイコンで確認することができる。
Nested Loopsとは?
Nested Loops 操作は、内部結合、左外部結合、左半結合、左反半結合の各論理操作を実行します。 ネステッド ループ結合では、外部テーブルの行ごとに内部テーブルが検索されます。検索には、通常はインデックスが使用されます。 クエリ プロセッサにより、予想コストに基づいて、内部入力でインデックスを検索する場所の絞り込みを向上するために、外部入力を並べ替えるかどうかが判断されます。 実行される論理操作に基づいて、 Argument 列の述語 (省略可能) に適合するすべての行が、該当する行として返されます。 最適化された属性が True に設定されている場合、最適化された Nested Loop (または一括並べ替え) が使用されることを意味します。
https://docs.microsoft.com/ja-jp/sql/relational-databases/showplan-logical-and-physical-operators-reference?view=sql-server-ver15
Repartition Streamsとは?
Repartition Streams 操作 (または交換反復子) では、複数のストリームを使用して、複数のレコード ストリームが生成されます。 レコードの内容と形式は変更されません。 クエリ オプティマイザーでビットマップ フィルターが使用される場合は、出力ストリームの行数が少なくなります。 入力ストリームの各レコードは、1 つの出力ストリームに配置されます。 この操作で順序を保持する場合、すべての入力ストリームが並べ替えられ、いくつかの並べ替え済みの出力ストリームにマージされる必要があります。 出力をパーティション分割する場合、 Argument 列に PARTITION COLUMNS:() 述語とパーティション列が設定されます。出力を並べ替える場合、 Argument 列に ORDER BY:() 述語および並べ替える列が表示されます。 Repartition Streams は論理操作です。 この操作は、並列クエリ プランのみで使用されます。
https://docs.microsoft.com/ja-jp/sql/relational-databases/showplan-logical-and-physical-operators-reference?view=sql-server-ver15
実行しているSQLに変更はない。ただ、統計情報のサンプリング数は変更していたのでSQL Serverのオプティマイザーの判断が変わったと推測している。
実際のクエリではないが、以下のような構造となっているクエリ
SELECT
*
,c.pricesum
FROM tableA a --←これを定義するとパフォーマンス劣化が著しい
LEFT JOIN tableB b ON a.storeid = b.storeid
/*↓問題のサブクエリ*/
LEFT JOIN (
SELECT
storeid
,sum(price) as pricesum
FROM tableA a
GROUP BY storeid
) c on a.storeid = c.storeid
/*↑問題のサブクエリ*/
WHERE a.ymd >= '20200101'
試したこと
with句を使ってサブクエリを実行してみても同様の結果だった。「left join」で結合するだけなら高速であるが、サブクエリで店舗毎に合計(Sum)している「pricesumカラム」をトップレベルのselectで定義すると遅延する。
インデックスを追加してもパフォーマンスは変わらなかった。
解決方法
まず、一時テーブルを作成し集計結果をテーブルに格納する。一時テーブルをメインのクエリ内で外部結合をすることで以前と同様のパフォーマンスに戻すことができた。
/* 一時テーブルを作成 */
CREATE TABLE #TEMPTABLE(
storeid int NOT NULL
,pricesum decimal(10,2) NOT NULL
)
;
/* storeidは主キーに定義する */
ALTER TABLE #TEMPTABLE ADD PRIMARY KEY CLUSTERED
(
storeid ASC
)
/*副問い合わせの結果を一時テーブルに登録する*/
INSERT INTO #TEMPTABLE
SELECT
storeid
,sum(price) AS pricesum
FROM tableA
GROUP BY storeid
;
/*一時テーブルと結合する*/
SELECT
*
,c.pricesum
FROM tableA a --←これを定義するとパフォーマンス劣化が著しい
LEFT JOIN tableB b ON a.no = b.no
LEFT JOIN #TEMPTABLE c ON a.storeid = c.storeid
WHERE a.ymd >= '20200101'
;一時テーブルの作成方法



コメント